Ещё учитывая то, что я сейчас третий год на Raspberry Pi 4 / 8 Gb сижу, тогда как основной ПК включался года полтора назад с единственной целью - успеть скопировать файл с паролями от нужных аккаунтов на флешку. После чего, не прошло и минуты - BSOD'нуло…
То есть, все VMware с Windows'9x, Windows'XP, Windows'8, а также с Visual Studio 6, Proteus, Quartus и т.д. - на диске ПК, который BSOD'ами кидается в самый неподходящий момент…
Менял БП и Винт: дело, ИМХО, в материнке…
Тем самым, все практические наработки эмуляторов и т.д. - всё на локальном диске: В сеть внутренние файлы не кидал…
Приходится в рамках Raspberry Pi всё восстанавливать по памяти и по опыту…
Из последних разработок (из-под Raspberry Pi) сейчас имеется уже симулятор MMX/SSE отладки (статья на Хабре) и текстовый редактор для РАДИО-86РК с поддержкой светового пера (ссылка), чтобы не терять спортивной 8-битной формы.
Вот думаю его приспособить движок под обновлённый эмулятор Койяанискаци.
В этом свете, производительность, действительно, не имеет никакого значения.😂
Четыре года назад я данный бутафорский процессор за пару часов схематикой в Logisim намалевал. Однако, уж четвёртый год никак его до ума довести не могу.
Сами видите, он сложнее Z80 уже получается, а с его этими маргиналами, сопроцессорами и безразмерным регистровым файлом - дотягивает до i8086 и не знаю, как вообще разобраться!
Это как-то бездонная архитектура получилась.
Хоть бери и описывай три варианта: Mini / Classic / Pro.
Естественно, я сейчас барахтаюсь где-то в промежутке между Classic и Pro…😇
Я специально указал на проблемы архитектур Intel в частности, так как у них:
Флаговый регистр имеет какие-то резервные биты #1, #3 и #5. Они резервные уж начиная с i8080 и как рудимент - так ими и остаются
Инструкция LEA вторым операндов всегда принимает указатель. При попытке использовать обычный регистр получаем исключение
Инструкция LOOP была некогда классной, а теперь всюду рекомендуют избегать её использования
Инструкции ENTER/LEAVE так браво ввели для Паскаля, а на деле - замусорили таблицу команд, как и AAA, AAD, AAM, AAS
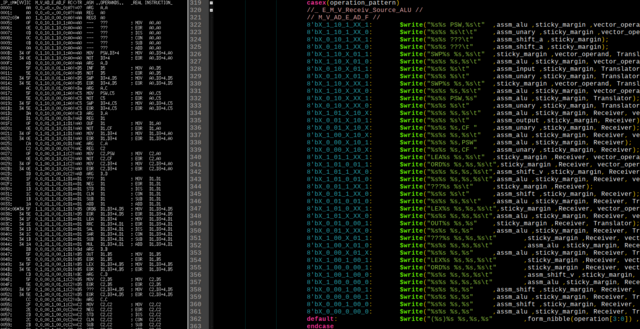
У меня единственным перегруженным сейчас является набор АЛУ-команд, как можно видеть чуть выше из логов, где появились всякие знакомые LEA, XLAT и т.д.
А всего-то, я строго запретил использовать флаговый регистр A0 за операнд и указывать D-порт, где не следует…
Сейчас у меня концептуально ещё веселее:
кодом AB указываем, что левый операнд-приёмник - группа регистров A, правый операнд-транслятор - группа регистров B
кодом A1 указываем, что конкретно операнд-приёмник - регистр A1
кодом A2 указываем, что мы - передумали и операнд-приёмник A2. Так дурачиться нельзя: Раз был A1 и теперь A2 - получайте A12!
кодом C3 указываем, что выбираем операнд-приёмник - регистр C3. Но, как же так, если о группе регистров C пока и речи не было? Получайте синтетическую инструкцию «MOV A12,C3»
кодом C4 указываем, что мы всё ещё не готовы остановиться и упорно выбираем снова сторонний регистр! Вот тут то получаем синтетическую инструкцию «MOV A12,C34»
Вы поймали волну?😉
Вроде бы всё просто, но у процессора как будто появилось чутьё контекста кода: Он запоминает предыдущее действие и позволяет последовательно его детализировать.
А какой программист откажется от такого вот безразмерного регистрового файла?
То есть, парадигма красивого машинного кода в HEX-дампе позволяет кодировать такие вот простые и изящные инструкции!😆
А как Вам такое?
код «A1» всегда указывает на регистр A1 как инструкция «REG A1»…
код «A1 A0» по новой интерпретации однотипных кодов как инструкция «REG A10» указывает на регистр A10
код «A0 A1» при таком принципе будет интерпретирован как инструкция «REG A01», что по сути «REG A1» при игнорировании лидирующих нулей (NOP'ы?)
код «A0 A0 A1» как инструкция «REG A001» по сути - снова «REG A1» (с NOP'ами???)
Вот как тут быть?
Как вариант, есть такая черновая интерпретация:
код «A0 A1» условно считать за укороченный «REG A101»: Здесь лидирующий ноль включает режим единиц первого десятка сотни
код «A0 A0 A1» условно считать за укороченный «REG A1001»
код «A0 A9 A9» условно считать за укороченный «REG A1099»
Но, такое усложнение только больше всё запутает и маргинализировать лидирующие нули я просто опасаюсь чисто из концептуальных соображений: Маргиналы и так усложнили базовые понятия об архитектуре и кодировании алгоритмов, но не завели её в «бездну эзотерических битовых полей», как это произошло с префиксами Z80 и в x86.
Например, все новые инструкции (INC/DEC/CLR/SET/NOT/LEA/ORD/LEX) порождаются из простейших понятий о том, что:
регистр A0 (PSW) не может участвовать в операциях АЛУ как активный операнд-приёмник и/или операнд-источник
регистры D-группы как 16-битные регистровые пары не могут смешиваться с 8-битными одиночными регистрами в операциях АЛУ
регистры D-группы могут представлять порты УВВ как источники в 8-битных операциях АЛУ
один и тот же регистр не может в большинстве операциях АЛУ быть первым и вторым операндом одновременно
Уже эти правила порождают десятки исключительных ситуаций с новыми полезными инструкциями (даже с игнорированием маргиналов😞
+--------------> Имеется "маргинальный префикс"
|
| +------------> Имеется "векторный префикс"
| |
| | ++---------> Приёмник - либо A0/PSW, либо порт Dj, либо 16-битная регистровая пара Bn:Cn
| | ||
| | || +-------> Приёмник и источник - один РОН или регистровая пара
| | || |
| | || | ++----> Приёмник - либо A0/PSW, либо порт Dj, либо 16-битная регистровая пара Bi:Ci
| | || | ||
| | || | || +--> Признак FOR/MOV - не АЛУ-операции
| | || | || |
M V AD E AD F
X_1_10_1_XX_1: MOV PSW,[V] ; Чтение PSW из ОЗУ
X_1_10_1_XX_0: UNARY [V] ; Унарные INC/DEC/CLR/SET/NOT над ОЗУ
X_0_10_1_XX_1: MOV??? PSW,PSW ; 1 шт. !!!reserved!!!
X_0_10_1_XX_0: UNARY?? PSW ; 5 шт. !!!reserved!!!
X_1_10_X_01_1: SWAP [V],Dn ; XCHG ОЗУ и 16-битной пары
X_1_10_X_01_0: ALU_OP [V],Dn ; АЛУ-ADD/SUB/AND/OR/EOR 16-битного ОЗУ и пары
X_0_10_X_01_1: INF Dj ; MOV PSW,Dj - Попытка ввода из порта (результат - в CF)
X_0_10_X_01_0: UNARY Dn ; 16-битные унарные INC/DEC/CLR/SET/NOT
X_1_10_X_XX_1: SWAP [V],Rn ; XCHG ОЗУ и 8-битного РОН
X_1_10_X_XX_0: ALU_OP [V],Rn ; АЛУ-ADD/SUB/AND/OR/EOR ОЗУ и 8-битного РОН
X_0_10_X_XX_1: MOV PSW,Rn ; Чтение PSW из РОН
X_0_10_X_XX_0: UNARY Rn ; Унарные INC/DEC/CLR/SET/NOT над РОН
X_1_01_X_10_X: ALU/MOV Dn,[V] ; АЛУ-ADD/SUB/AND/OR/EOR и MOV пары с 16-битным ОЗУ
X_0_01_X_10_1: OUF Dj ; MOV Dj,PSW - Попытка вывода в порт (результат - в CF)
X_0_01_X_10_0: UNARY Dn,CF ; Унарные INC/DEC/CLR/SET/NOT над парой при условии CF
X_1_00_X_10_X: ALU/MOV Rn,[V] ; АЛУ-ADD/SUB/AND/OR/EOR и MOV РОН с ОЗУ
X_0_00_X_10_1: MOV Rn,PSW ; Загрузка PSW в РОН
X_0_00_X_10_0: UNARY Rn,CF ; Унарные INC/DEC/CLR/SET/NOT над РОН при условии CF
X_1_01_1_XX_1: LEA Dn,[V] ; Загрузка "эффективного адреса" в регистровую пару
X_1_01_0_01_1: ORD Dn,[V],Di ; Dn = (MAX(Dn, Di) - ОЗУ) >> 1
X_1_01_X_01_0: ALU_OP Dn,[V],Di ; 16-битная ADD/SUB/AND/OR/EOR ОЗУ с Di, результат в Dn
X_0_XX_1_XX_1: MOV??? R,R ; 1 шт. Холостая пересылка (NOP???)
X_0_01_1_XX_0: UNARY?? Dn ; 5 шт. 16-битные унарные INC/DEC/CLR/SET/NOT (повтор!!!)
X_1_01_0_XX_1: LEX Dn,[V],Ri ; 16-битный XLAT: MOV Dn,[V+2*Ri]
X_1_01_X_XX_0: ALU_OP Dn,[V],Ri ; 8-битная ADD/SUB/AND/OR/EOR ОЗУ с РОН, результат в 16-бит Dn
X_0_01_0_00_1: MOV Dj,Ri ; Аналог OUT Dj,Ri - вывод в порт
X_0_01_X_XX_0: ALU_OP Dn,Ri ; 16-битная ADD/SUB/AND/OR/EOR Dn с 8-битным Dn
X_1_0X_X_01_1: MOV??? R,[V],Dj ; 1 шт. !!!СТРАННАЯ ОПЕРАЦИЯ!!!
X_1_0X_X_01_0: ALU_OP R,[V],Dj ; 8-битная ADD/SUB/AND/OR/EOR ОЗУ с портом Dj, результат в РОН
X_0_0X_X_01_X: ALU/MOV R,Dj ; АЛУ-ADD/SUB/AND/OR/EOR или MOV (IN R,Dj) РОН с портом Dj
X_1_0X_1_0X_1: LEX R,[V] ; 8-битный XLAT: MOV R,[V+R]
X_1_0X_0_0X_1: ORD R,[V],R' ; R = (MAX(R, R') - ОЗУ) >> 1
X_1_0X_X_01_X: ALU/MOV R,[V],R' ; ADD/SUB/AND/OR/EOR или MOV ОЗУ с R', результат в РОН
X_0_0X_X_01_X: ALU/MOV R,R' ; ADD/SUB/AND/OR/EOR или MOV ОЗУ с R', результат в РОН
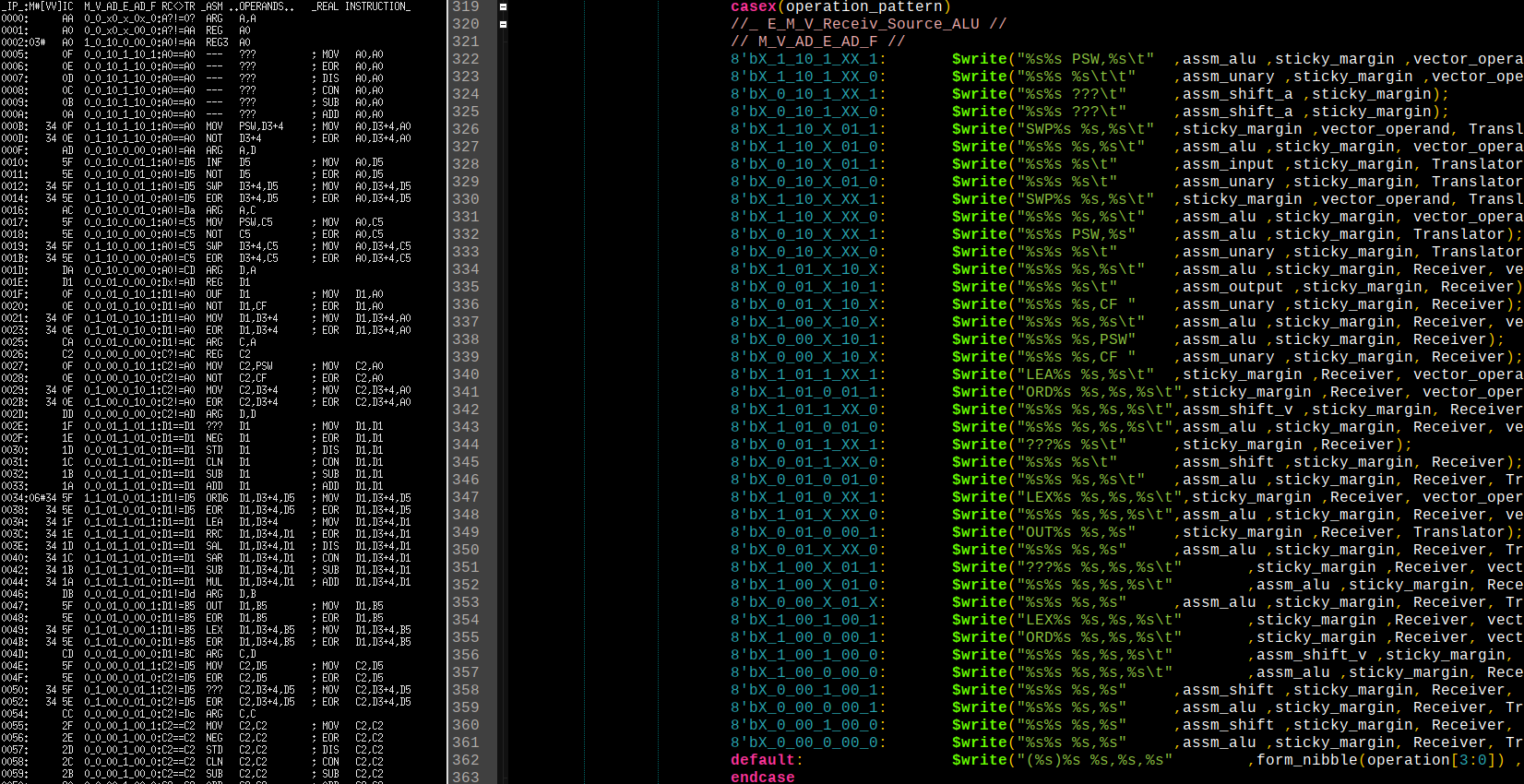
Примеры:______________________________________________________________________________________________
AA A0 12 0F MOV PSW,[D1+2] ; На самом деле, полная мнемоника операции - MOV A0,[D1+2],A0
AA A0 12 0E NOT [D1+2] ; На самом деле, полная мнемоника операции - EOR A0,[D1+2],A0
AD A0 12 3F SWAP [D1+2],D3 ; На самом деле, полная мнемоника операции - MOV A0,[D1+2],D3
AD A0 1F INF D1 ; На самом деле, полная мнемоника операции - MOV A0,D1
AD A0 1E NOT D1 ; На самом деле, полная мнемоника операции - EOR A0,D1
AB A0 12 3F SWAP [D1+2],B3 ; На самом деле, полная мнемоника операции - MOV A0,[D1+2],B3
AB A0 12 3E EOR [D1+2],B3 ; На самом деле, полная мнемоника операции - EOR A0,[D1+2],B3
AB A0 1F MOV PSW,B1 ; На самом деле, полная мнемоника операции - MOV A0,B1
AB A0 1E NOT B1 ; На самом деле, полная мнемоника операции - EOR A0,B1
DA D1 0F OUF D1 ; На самом деле, полная мнемоника операции - MOV D1,A0
DA D1 0E NOT D1,CF ; На самом деле, полная мнемоника операции - EOR D1,A0
DD D1 23 1F LEA D1,[D2+3] ; На самом деле, полная мнемоника операции - MOV D1,[D2+3],D1
DD D1 23 4F ORD D1,[D2+3],D4 ; На самом деле, полная мнемоника операции - MOV D1,[D2+3],D4
DC D1 23 4F LEX D1,[D2+3],C4 ; На самом деле, полная мнемоника операции - MOV D1,[D2+3],C4
P.S.: Но это всё - лирика…



")