ppram5
Участник-
Постов
32 -
Зарегистрирован
-
Посещение
Весь контент ppram5
-
В общем немного подразобрался и поэкспериментировал. Что касается времени преобразований: arm_rfft_fast_f32 (4096) идет за 7,7мс. arm_rfft_q31 - 10,2мс. Разница 2,5мс, float быстрее, хоть и не немного. Время приведения uint16_t к f32 перегоном в цикле 1,3мс. С коллегами произвели оценку необходимой точности - в q15 не влезаем. Напрямую грузить данные из апц через дма с левым сдвигом можно, но придется все равно сдвигать число на один бит вправо, т.к. первый бит знаковый. Все равно цикл прогонять. В итоге если сделать: фильтр+ФТТ+корреляция *10, думаю преимущество для float набежит на пару-тройку десятков миллисекунд.
-
Как все напишу - обязательно поделюсь результатами и проведу сравнение.
-
У fixed*32 24 мантисса бита и 8 бит под дробную часть и без знака, у float*32 - мантисса 23 и экспонента 8 и один под знак. И где выше Динамика? И во сколько раз? Как вы заметили, в ARM далеко не дураки придумали, конечно они умеют работать с фиксированной точкой, но зачем же тогда они слепили целый FPU и пихают их в недорогие ками? Вообще обо всем этом очень подробно тут: https://www.st.com/content/ccc/resource/technical/document/application_note/group0/c1/ee/18/7a/f9/45/45/3b/DM00273990/files/DM00273990.pdf/jcr:content/translations/en.DM00273990.pdf А вот тут сравнение размерности float и fixed. И о преимуществе применения FPU: http://microsin.net/programming/arm/stm32-floating-point-unit.html Дабы не копаться процитирую: Аппаратные вычисления FPU ускоряют алгоритм множества Жюлиа в 12.5 раз при использовании float, и в 7.2 раза при использовании double. Не требуется никакой модификации кода, FPU активируется опциями компилятора. Также FPU позволяет расширить диапазон точности. Таким образом, STM32 FPU реализует очень быстрые вычисления для чисел float и double, что очень важно для точных систем регулирования, обработки звука, декодирования звука или цифровой фильтрации. Интересная у нас дискуссия вышла, казалось бы из простого вопроса 🙂 Но еще раз повторюсь - float только при наличии FPU, иначе float станет злом, а fixed будет рулить. А лучше уж оставить uint если это возможно.
-
А вот вопрос, fractional это fixed или float? В терминологии библиотеки CMSIS-DSP: fixed это Q31. Который кстати в библиотеке определен как typedef int32_t q31_t Можно и q31 обрабатывать, но на камне с FPU, это как то не правильно. f32 выигрывает, хоть и не так много. Скорость сильно зависит от того какие преобразования выполняются. Я все таки предполагал, что fractional - float, а не fixed. Хотя могу и ошибаться, я так глубоко не зарывался dsPIC. Ибо какой смысл крутить целочисленную арифметику на FPU, если она прекрасно работает и на основном процессоре. У Q31 (фиксированная точка) есть ряд недостатков, нужно быть очень аккуратным при выполнении мат операций ибо легко налететь на переполнение и неверный результат. О чем ST честно предупреждает. Более низкая точность чем во float. Данные с АЦП для Q31 тоже приводить нужно в STM32. Хотя надо попробовать левое выравнивание в настройках АЦП - по идее может прокатить. Вообще у ST есть очень толковое описание на предмет f32 и Q31, не помню, где лежит. Еще float удобен для отладочного вывода в порт с банальным printf(%f). Q31 на приемной стороне не поймут, как не понимает его и printf (ну разве что как целое).
-
Fractional - дробь Integer - целое Есть ведь разница получить например 2354 или 0,458. В чем хранить 0,458? Вроде как логично, что в float?
-
Общего назначения: PIC32MZ, может и другие умеют, не копался. https://static.chipdip.ru/lib/013/DOC004013135.pdf стр 446 REGISTER 28-1: ADCCON1: ADC CONTROL REGISTE bit 23 FRACT: Fractional Data Output Format bit 1 = Fractional 0 = Integer Специализированные: dsPIC33, но там вообще навернуто: FORM<2:0>: Data Output Format bits 011 = Signed Fractional 16-bit (DOUT = 0000 0000 0000 0000 sddd dddd dd00 0000) 010 = Fractional 16-bit (DOUT = 0000 0000 0000 0000 dddd dddd dd00 0000) 001 = Signed Integer 16-bit (DOUT = 0000 0000 0000 0000 ssss sssd dddd dddd) 000 = Integer 16-bit (DOUT = 0000 0000 0000 0000 0000 00dd dddd dddd) 111 = Signed Fractional 32-bit (DOUT = sddd dddd dd00 0000 0000 0000 0000) 110 = Fractional 32-bit (DOUT = dddd dddd dd00 0000 0000 0000 0000 0000) 101 = Signed Integer 32-bit (DOUT = ssss ssss ssss ssss ssss sssd dddd dddd) 100 = Integer 32-bit (DOUT = 0000 0000 0000 0000 0000 00dd dddd dddd) Данные выдает АЦП, и формат определяется настройками АЦП, а ДМА пересылает все что ей скормят не особо интересуясь что там, шишь бы размерность совпадала.
-
arm_rfft_q15 - Пробовал, работает, чуть медленнее чем флоат.
-
Видимо я как то неправильно задал вопрос: Есть АЦП, формат его выходных данных от 12 до 6 бит (можно настроить) и выравнивание по левому или правому краю. Как настроим так и будет. Есть ДМА - она "перекладывает" данные АЦП в соответствующий массив памяти. Причем делает это без участия центрального процессора (ядра) МК. Чтобы данные были положены в память некорректно типы данных должны совпадать и видимо в STM32 это может быть только uint. Собственно вопрос был в том, можно ли указать тип данных float и складировать в память уже в готовом к применению формате, как это сделано в более развитых МК. При этом не требуется ни выделение памяти, ни цикл, ни, соответственно, участие процессора. Теоретически можно переписать функцию чтобы она внутри себя делала этот перегон без буфера, но от цикла не избавиться и выполнять его все равно придется процессору. К тому же переписывать готовые библиотеки не очень правильно - теряется смысл применения библиотек.
-
Функция требует входных данных в f32. void arm_rfft_fast_f32 ( const arm_rfft_fast_instance_f32 * S, float32_t * p, float32_t * pOut, uint8_t ifftFlag ) https://www.keil.com/pack/doc/CMSIS/DSP/html/group__RealFFT.html#ga5d2ec62f3e35575eba467d09ddcd98b5 Поскольку есть модуль FPU и библиотека под него заточена - все крутиться очень быстро, если память не изменяет, на 2048 уходило около 4мс - вполне устраивает, у меня не непрерывный поток. Да и другие функции ЦОС требуют f32. Если сунуть функции rFFT данные в uint - будет полная ересь, пробовал 🙂 Ну и компилятор орать начинает. Пробовал алгоритм rFFTс uint - без применения FPU (рукописный) - в несколько раз дольше выходит. Если сделать то жде самое без FPU (пробовал на 32F103) тоже реально долго выходит. Тоже долго ломал мозг - зачем вообще этот флоат - пока сам не попробовал.
-
Чтобы потом делать FFT и прочие "нехорошие" вещи с сигналом 🙂 Пока это работает так: for (i=0; i<FFT_SAMPLES; i++) // По всем отсчетам { inputSignal[i]=(float32_t)adc[i]; } // Подготовливаем преобразование status = arm_rfft_fast_init_f32(&S, FFT_SAMPLES); // Выполняем релаьное преобразование arm_rfft_fast_f32(&S, inputSignal, outputSignal, 0); Библиотека SMSIS-DSP. Сейчас с фильтрацией перед FFT разбираюсь. Скользящее среднее - на ура, надо опробовать медианный фильтр и экспоненциальное бегущее среднее. Ну и продумать реализацию на FPU. В последней версии появилась возможность делать FFT над float16_t надо попробовать. ПС: А вот с алгоритмами анализа результатов ЦОС - пока не знаю даже куда копать... Кроме обучения нейросетей в голову ничего не приходит 😞
-
Дабы не плодить темы, спрошу здесь: STM32F401. Работает АЦП + DMA, результат складывается в uint16_t, размером 4096 отсчетов, потом с помощью цикла перегонять все это в float32_t. Приходиться выделять память под еще один буфер и время на выполнение. Можно ли сделать так, чтобы результат от АЦП сразу получался в Float32_t, а лучше в fliat16_t? Подобные вещи можно например делать в dsPIC и некоторых PIC32, а в STM32?
-
Ручной выбор VCO в MAX2871
ppram5 ответил ppram5 тема в RF & Microwave Design
Быстро - вся операция по дерганью выходит примерно как 4 клока по времени, но можно конечно попробовать и лишний байт зарядить - посмотреть как МС отреагирует. -
Ручной выбор VCO в MAX2871
ppram5 ответил ppram5 тема в RF & Microwave Design
Количество частот в общем случае не более 100 или 200. Именно чтобы не зависеть от разброса каждого экземляра МС и от внешней температуры (уличная эксплуатация) я и возился с таким методом. К тому же планирую добавить таймер, проверяющий наличие генерации - если сорвалась - перекалибровка. -
Ручной выбор VCO в MAX2871
ppram5 ответил ppram5 тема в RF & Microwave Design
В итоге - победил. Причина действительно оказалась в реализации чтения. А конкретно в этой фразе из dataseet: "Finally, send 1 period of the clock." В общем, нужно дать один дополнительный тактовый импульс на CLK пред чтением данных. Поскольку SPI аппаратный - отключаю вывод от модуля SPI, передергиваю его и возвращаю на место. К тому же нужно сдвинуть полученные данные на два бита влево. Все заработало как нужно. Сначала выясняю какой VCO выбран в автомате для каждой частоты, а затем шишу их с ручным выбором. Рабочий код - вдруг кому то пригодиться... uint32_t SPI_ReadDWord() // Функция чтения { uint32_t spi_data=0; // Считанное значение uint8_t spi_packet[4]={0}; // Байтовый массив uint8_t i=0; LE_LAT=0; // Запись байта в SPI SPI1_ExchangeByte(0x00); // Запись байта в SPI SPI1_ExchangeByte(0x00); // Запись байта в SPI SPI1_ExchangeByte(0x00); // Запись байта в SPI SPI1_ExchangeByte(0x06); // Запись байта в SPI LE_LAT=1; // Запись с адресом R6 RB2PPS = 0x00; //RB2->LAT; RB2_SetHigh(); // Один тактовый импульс RB2_SetLow(); RB2PPS = 0x0D; //RB2->MSSP1:SCK1; for ( i = 0; i < 4; i++) { spi_packet[i] = SPI1_ExchangeByte(0x00); // Чтение } for ( i = 0; i < 4; i++) { spi_data |= spi_packet[i]; if ( i != 3) spi_data = spi_data << 8; } spi_data=spi_data<<2; // Сдвиг на два бита return spi_data; } -
Ручной выбор VCO в MAX2871
ppram5 ответил ppram5 тема в RF & Microwave Design
Продолжил изыскания... Все-таки, что то не так с чтением. Пробовал разные вариации на тему чтения по примеру разных исходных кодов найденных в сети - результата нет. Зато обнаружил, что при изменении скорости SPI читаются разные данные (при 1МГц и 4МГц - одно значение, а при 16МГц - другое). А вот запись во всех случаях идет корректно и МС встает на нужную частоту. Что еще странно - после окончания калибровки и просто записи - на выходе SPI от MAX2871 продолжают идти данные, хотя команды на чтения не давал. В общем буду искать лог. анализатор, без него никак. -
Ручной выбор VCO в MAX2871
ppram5 ответил ppram5 тема в RF & Microwave Design
Спасибо! Вечером попробую, может мне этой холостой передачи не хватает... Завтра отпишусь по результату. -
Ручной выбор VCO в MAX2871
ppram5 ответил ppram5 тема в RF & Microwave Design
Даташит 3-й версии, там как раз добавлен ручной выбор VCO. ID с совпадает. Да и в остальном все работает штатно. Сегодня попробую вечером подключить сниффер на SPI - посмотреть, что там реально. Несколько смущает, необходимость реверса бит при чтении - по идее такого не должно требоваться. -
Ручной выбор VCO в MAX2871
ppram5 ответил ppram5 тема в RF & Microwave Design
пробовал ставить задержки разные от 1мкс до 200мс после ожидания LD - эффекта никакого, читается то же значение. Склоняюсь к мысли, что все-таки что то не так с чтением R6... -
Ручной выбор VCO в MAX2871
ppram5 ответил ppram5 тема в RF & Microwave Design
PLL включен, только работает он на одном заранее определенном VCO, смысл в том, чтобы не тратить время на его автоматический выбор. Не понимаю, как знание напряжения Vtune мне поможет? Насколько я представляю, если мы узнали какой VCO был выбран в автоматическом режиме - мы можем его выбрать и в ручном, при тех же настройках и для той же частоты... При выполнении калибровки Vtune примерно 1,3В, а при попытки его задать вручную, значение стремиться к верхнему пределу примерно 3,27. При его подборе вручную - все работает, напряжение около 1,3В, вот только номер VCO там совсем другой выходит. Так по автовыбор выходит VCO 27, а работает по подбору на VCO 40. -
Ручной выбор VCO в MAX2871
ppram5 опубликовал тема в RF & Microwave Design
Суть проблемы: нужно быстро менять частоту в MAX2871. Поэтому был сделан ручной выбор VCO. Подобрали массив со значением VCO. На первых двух партиях все было хорошо. Затем столкнулись с тем, что на партии в 50 штук примерно 1/4 не заработала - приходиться менять VCO (те подбирать под каждую плату), что есть очень трудоемкий процесс. Решил сделать как советует даташит - прогнать по всем частотам в режиме автовыбора, запомнить номера VCO, а затем использовать номера в режиме ручного выбора. (стр. 27 VCO Manual Selection Operation) А вот не работает! Читаю, записываю, а генерация на другой частоте, подбираю VCO - все в порядке. В данный момент - делаю только для одной частоты, а не для всей сетки частот. Вот собственное код... volatile uint32_t R3=0; // Одиносное содержимое R3 volatile uint32_t R6=0; // Одиносное содержимое R3 uint8_t RevByte(uint8_t a) // Обратный порядок битов в байте { a=((a>>1) & 0x55) | ((a<<1) & 0xAA); a=((a>>2) & 0x33) | ((a<<2) & 0xCC); a=((a>>4) & 0x0F) | ((a<<4) & 0xF0); return a; } void SPI_WriteDWord(uint32_t a) // Функция записи двойного слова в SPI { uint8_t b=0; // Временная переменная для байта LE_LAT=0; // Запись байта в SPI b=a>>24; // Выбор четвертого (старшего) байта SPI1_ExchangeByte(b); // Запись байта в SPI b=a>>16; // Выбор третьего байта SPI1_ExchangeByte(b); // Запись байта в SPI b=a>>8; // Выбор второго байта SPI1_ExchangeByte(b); // Запись байта в SPI b=a; // Выбор первого (младшего) байта SPI1_ExchangeByte(b); // Запись байта в SPI LE_LAT=1; } // Загрузка всех настроек в MAX2871 void SetMAX2871(uint32_t R0, uint32_t R1, uint32_t R2, uint32_t R3, uint32_t R4, uint32_t R5) { SPI_WriteDWord(R5); SPI_WriteDWord(R4); // Запись регистра SPI_WriteDWord(R3); SPI_WriteDWord(R2); SPI_WriteDWord(R1); SPI_WriteDWord(R0); } uint32_t SPI_ReadDWord() // Функция чтения { uint32_t spi_data=0; // Считанное значение uint8_t spi_packet[4]; // Байтовый массив uint8_t i=0; SPI_WriteDWord(0x00000006); // Запись с адресом R6 for ( i = 0; i < 4; i++) { spi_packet[i] = SPI1_ExchangeByte(0x00); // Чтение } for ( i = 0; i < 4; i++) { spi_data |= RevByte(spi_packet[i]); // Формируем резусльтат с изменнеием порядка битов //spi_data |= spi_packet[i]; if ( i != 3) spi_data = spi_data << 8; } return spi_data; } void CalibrateVCO() // Калибровка на нужные VCO { uint8_t i=0; uint32_t a=0; SPI_WriteDWord(0x00001F23); // Пишем R3 с атовыбором VCO SPI_WriteDWord(0x005C0110); // Пишем R0 while (LD_PORT==0) {}; // Ждем захвата R6=SPI_ReadDWord(); // Читаем R6 a=R6; a=a<<23; // Формируем R3 на основании VCO из R6 a=a & 0xFC000000; a=a | 0x02001F23; R3=a; } void main(void) { SYSTEM_Initialize(); uint16_t i2g=0; uint32_t a=0; uint8_t b=0; // Временная переменная для байта uint8_t i=0; // Enable the Global Interrupts //INTERRUPT_GlobalInterruptEnable(); // Disable the Global Interrupts //INTERRUPT_GlobalInterruptDisable(); // Enable the Peripheral Interrupts //INTERRUPT_PeripheralInterruptEnable(); // Disable the Peripheral Interrupts //INTERRUPT_PeripheralInterruptDisable(); SPI1_Open(SPI1_DEFAULT); // Открытие SPI // Инициализация MAX2871 RFPDN_LAT=0; CE_LAT=1; LE_LAT=1; SetMAX2871(0x07D00000,0x400103E9,0x11035F42,0x00001F23,0x60A140FC,0x00440005); __delay_ms(25); SetMAX2871(0x07D00000,0x400103E9,0x11035F42,0x00001F23,0x60A140FC,0x00440005); __delay_ms(20); SetMAX2871(0x005C0110,0x200101A1,0x10005F42,0x00001F23,0x629080FC,0x00440005); RFPDN_LAT=1; // Конец инициализации MAX2871 __delay_ms(2000); CalibrateVCO(); __delay_ms(1000); while (1) { LED2_LAT=~LED2_LAT; SPI_WriteDWord(R3); // Пишем анее заготовленное R3 SPI_WriteDWord(0x005C0110); // Пишем R0 while (LD_PORT==0) {}; // Ждем захвата i2g++; if (i2g==83) {i2g=0;} // Сброс счетчика __delay_ms(1000); } } В чем может быть проблема? Может что то не так с чтением? Хотя ID микросхемы и адрес прочитанного регистра правильные. Читается так 01111000 00000000 00000000 11011110 [0x780000DE] R6 Читаю 01101110 00000000 00011111 00100011 [0x6E001F23] R3 Формирую и пишу - Не работает 10100010 00000000 00011111 00100011 [0xA2001F23] R3 Подгоняю - а так работает Может какие то особенности в настройках МС не учел? Куда копать? -
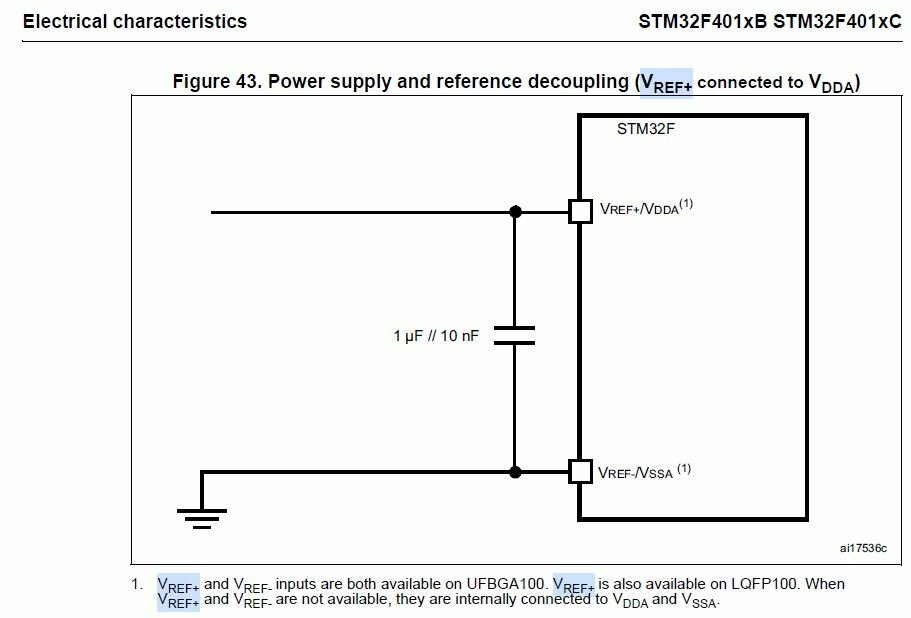
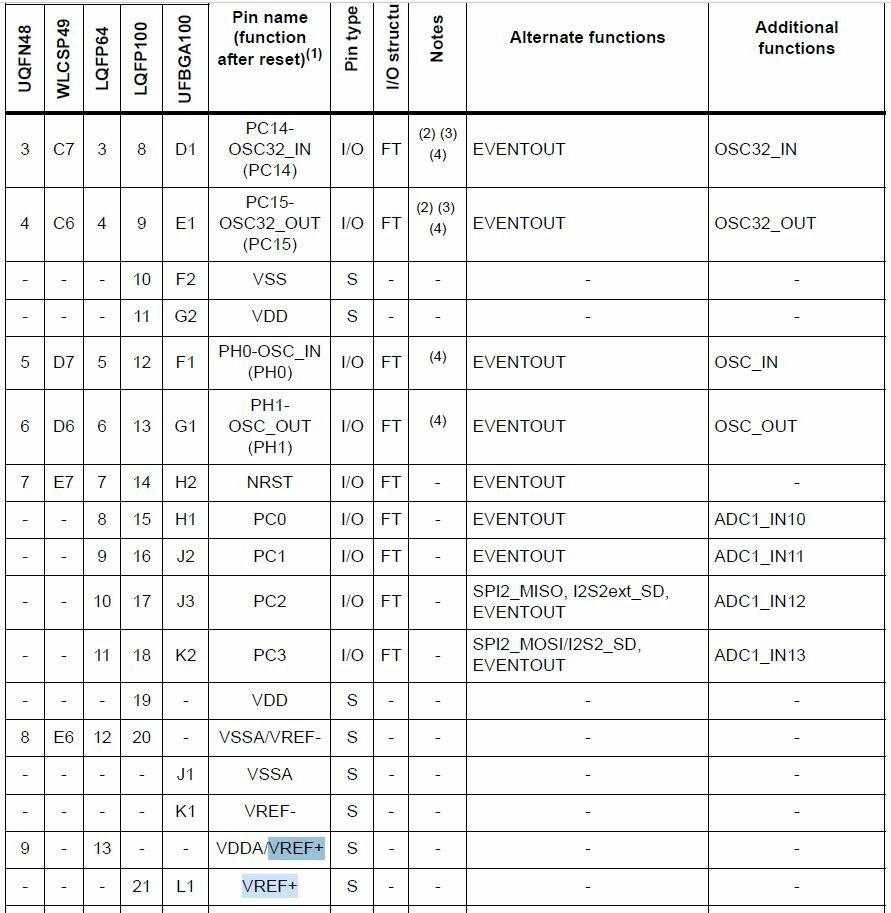
STM32G431 - за наводку спасибо! Xenia - не знаю откуда эта картинка и почему она расходиться с даташитом - но в родном даташит все ясно сказано: "VREF+ and VREF- inputs are both available on UFBGA100. VREF+ is also available on LQFP100. When VREF+ and VREF- are not available, they are internally connected to VDDA and VSSA." Таблица распределения выводов из того же документа это подтверждает. EFR32BGxx - использовать SoCs да еще и с радиотрактом внутри - явный перебор. Опять же, средства разработки / отладки / ну и цена. В принципе я бы с удовольствием остался на PIC-ах, применив ds33 - но дороговато, а в PIC24 - скоростенки не хватает и у ядра и у АЦП. Спасибо за ответы. Буду копать дальше.
-
Сначала суть проблемы, а потом собственно вопрос. Встал вопрос и переносе проекта с PIC18 на STM32 - основная причина - нехватка скорости АПЦ, скорости работы, плюс увеличение разрядности АПЦ с 10 до 12 бит. Раньше с STM32 почти не работал. Выбор пал на STM32F401CCU6. Тактовая устраивает, скорость АЦП тоже. Цена опять же вполне приемлемая. Начал изучать АПЦ - а там чудеса... Внутри не оказалось источника опорного напряжения, даже одного. В корпусах 48/64 вывода вывод Vref+ не выведен на ружу. Точнее он объединен с VDDA. Т.е. диапазон измеряемых напряжение от 0 до 3-х вольт (питания 3В). Vref- даже если в большом корпусе выведен отдельным выводом, он обязательно должен быть соединен с землей. Т.е. смещение шкалы АЦП такого вида не пройдет: на Vref- 0.4В, на Vref+ 2.2В. Измеряем в коридоре 1,8В. С PIC18 такое легко прокатывает. Собственно вопрос - есть ли среди STM32 камни с более развитым модулем АЦП? Чтобы можно было, бы хотя бы, просто на Vref+ подать 2В, не в монструозном корпусе.
-
Выбор элементов для УМ 2,4ГГц 4Вт.
ppram5 ответил ppram5 тема в RF & Microwave Design
Хороший файлик. Применительно к схеме включения HMT1008N1 - теоретический кпд - 50% (стр. 9 и 10 документа), на практике будет 30-40. Почему вы считаете, что "из фундаментального лимита 25%"? -
Выбор элементов для УМ 2,4ГГц 4Вт.
ppram5 ответил ppram5 тема в RF & Microwave Design
Само пе себе выделение тепла это нормально, вопрос с эффективным отводом тепла от транзистора. Корпус в дальнейшем будет иметь активное охлаждение (там кроме УМ еще много всего будет). Марка транзисторы как раз важна - важен корпус. Данный транзистор отдает тепло только через плату, вот я и рассчитывал на какие то другие варианты. Использование MHT1008N вместо MHT1006N уже позволит улучшить тепло-отведение. -
Выбор элементов для УМ 2,4ГГц 4Вт.
ppram5 ответил ppram5 тема в RF & Microwave Design
Менять режим крайне не желательно...