videoscan
-
Постов
58 -
Зарегистрирован
-
Посещение
Весь контент videoscan
-
Ошибка а Cosimulation (Vivado, HLS)
videoscan опубликовал тема в Среды разработки - обсуждаем САПРы
Народ! Имеется следующая ситуация. В Vivado, на HLS (Си), написана некая программа. Simulation и Synthesis проходит нормально. На этапе Cosimulation происходит ошибка (см. аттач). В тексте ошибки (см. выше) говорится, что не может открыть файл. Я проверил, файл есть, ничем от других подобных не отличается. Методом тыка определил, что Cosimulation не нравится большое число объявленных блоков памяти. Если его уменьшить (границы не нашел, но где-то около 500), все срабатывает. Кто-нибудь сталкивался с этим? Как бороться? У меня Vivado 2017.4 и Windows 7. Ресурсы FPGA не превысил. Чип - XCVU9P.
-
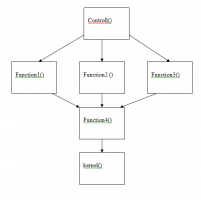
Т. е. так как на рис? А что помешает Vivado создать заодно и 3 экземпляра Function4 ? На самом деле решение есть: слить все 3 функции Function1-Function3 в одну здоровую и там сказать с помощью ALLCATION, что kernel нужен один, но как это некрасиво! И зачем мы Октябрьскую революцию делали, Си используем?
-
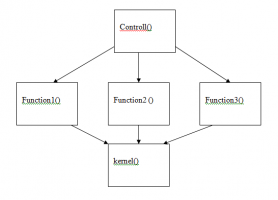
Народ! Проблема следующая. Есть программа на Vivado HLS со структурой как на рисунке: Верхняя функция - controll, в вызывает 3 разные подпрограммы function1, function2 и function3. Те в свою очередь обращаются к одной функции kernel, где происходит обработка данных. Функция kernel должна быть одна (на уровне RTL), потому как ресурсов она жрет немерено (1024 одних DSP блоков). Vivado HLS на этапе Sinthesis делает 3 RTL копии этой функции. Директива Allocation не помогает, она видит только функции в той подпрограмме, в которую вставлена. Кто-нибудь с этой проблемой сталкивался? Это решаемо?