


uragan90
-
Постов
210 -
Зарегистрирован
-
Посещение
Сообщения, опубликованные uragan90
-
-
Продам осциллограф (3 в 1 осциллограф, мультиметр, генератор) АКИП-4313/6, новый, в кейсе.
2 щупа, полный комплект!!!
Перешлю в любую точку России, посылкой или курьером за доплату!
Цена: 15000руб.
Обращаться на почту



-
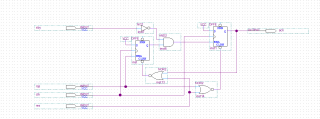
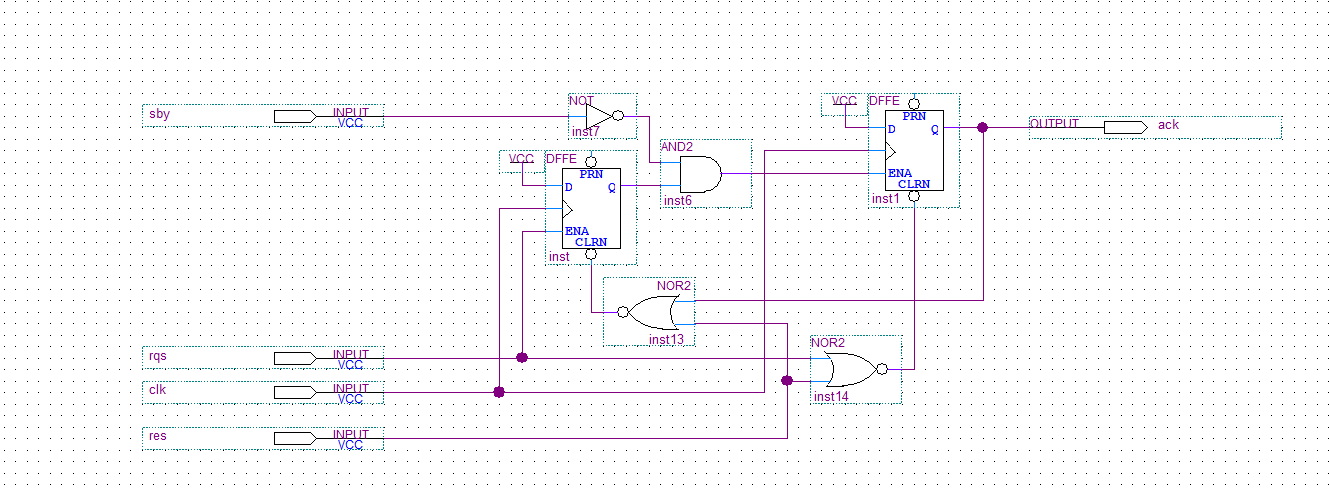
Начертал схемку которая решает практически половину всего дела :laughing:
Пока идёт запись sby мы можем записать в регистр запрос на чтение rqs и как только sby деактивируется, мы читаем байт и выставляем подтверждение ack, сбросив тем самым регистр чтения. При следующем запросе чтения мы сбросим подтверждение ack.
-
Приветствую!
Ой да что вы говорите! Не пугайте маленьких. Я еще на MAX7000 серии делал подобное и на статике и на просто DDR 100 MHz вполне себе рабочая была. У TC конечно память слегка неудобная для таких частот тут лучше синхронная статика подошла бы - придется помурыжится с таймингами чтобы вытянуть 100 MHz рабочей
Дерзайте!
Удачи! Rob.
Спасибо за поддержку!
Вот такая схема вырисовывается, остаётся реализовать конечный автомат.
8 разрядные данные гружу в регистр 16 бит и сигнал sby который теперь фактически сформировался и снизил частоту со 100 до 50Мгц.
Всем этим делом будет рулить конечный автомат, получать запросы на чтение и формировать подтверждение когда процесс записи деактивируется.
Ну как думаете, получится иль нет?
Текст счётчика адреса выглядит следующим образом:
module ADDR_counter( input res, input clk, input wr, input rd, output full, output empty, output [ADDR-1:0] Addr_Sram ); parameter ADDR = 5; // Параметр разрядности Адреса SRAM //--- Счётчики адресов чтения и записи ------------------------------ assign Addr_Sram = (wr) ? write_addr[ADDR-1 : 0] : read_addr[ADDR-1 : 0]; reg [ADDR:0] read_addr=0; always @(posedge clk or posedge res) //По такту чтения begin if(res) begin read_addr <= 0; end else begin if (rd) read_addr <= read_addr + 1'b1; else read_addr <= read_addr; end end //--- reg [ADDR:0] write_addr=0; always @(posedge clk or posedge res) //По такту записи begin if(res) begin write_addr <= 0; end else begin if (wr) write_addr <= write_addr + 1'b1; else write_addr <= write_addr; end end //--- Абработка флагов заполненности ФИФО ------------------------------ assign full = ((write_addr[ADDR-1:0] == read_addr[ADDR-1:0]) && (write_addr[ADDR] ^ read_addr[ADDR]))? 1'b1 : 1'b0; //Фифо полное assign empty = ((write_addr[ADDR-1:0] == read_addr[ADDR-1:0]) && (!(write_addr[ADDR] ^ read_addr[ADDR])))? 1'b1 : 1'b0; //Фифо пустое endmodule
А вот схема
-
задача проста как 2 копейки, вы мудрите...
первое: делаете 2 портовую память.
- это просто, она на частоте 100 МГц, то пишет в 1 адрес (если есть сигнал записи, или не пишите), то выставляет 2 адрес и читает. Получаете 50 МГц 2 портовую память.
У меня не двух портовая память CY7C1041DV33
У неё нет такой возможности обращения к одним и тем же данным по разным портам
-
Но данные приходят по 8 бит, а ширина шины данных ОЗУ 16 бит, что даёт ему возможность накопить слово и записать его одним махом. А пока оно копится - прочитать 16 бит для выдачи.
Именно так я и делаю!!! На частоте 100 я собераю данные по 8 бит, в регистр 16 бит. И того частота делится надвое. получается 50 Mhz. Память у меня 16ти разрядная и тем самым частота записи снижается. Читать я буду на частоте 10Mhz вот такой расклад получается, но проблема то в том что у меня 2 клоковых домина пересекающийся между собой!
-
Да, конечный автомат нужен. Но он простой, один-два триггера.
Вы с частотами-то поосторожнее. Тщательно просчитайте, возможно ли в принипе добиться от Вашей памяти такой растактовки. Тут нужен в клеточку лист бумаги, карандаш и мозг. Оно само всё покажет. Если основной клок 100МГц и данные поступают на каждом втором такте - то у Вас просто нет шансов даже на запись - каким образом сформировать управляющие сигналы? Или делать асинхронщину на RC цепях. У Вас нету системного подхода. Сначала - растактовка памяти (управляющие сигналы формируются из виртуального клока, и это будет явно не 100МГц, а 180, 166 или рядом). Критерий - максимально выжать быстродействие ОЗУ при условии, что управление идет почти на макс скорости (половина системного клока).
Вижу сам, что сумбурно. Вы сами сразу всё увидите, как растактовку ОЗУ нарисуете.
Да вроде работает, но видно что что то не то. Сложность заключается в проблеме моделирования шин с 3мя состояниями. В железе видно что работает но не так как хотелось бы
-
Тут правильно советуют - операция записи в ОЗУ имеет приоритет перед чтением.
Работу с ОЗУ разбиваем на циклы. Цикл состоит из записи и потом чтения.
Если есть запрос на запись - пишем. Если есть запрос на чтение - читаем, пока не появится запрос на запись или не кончится чтение.
Если одновременно присутствует и запрос на запись, и на чтение, то в каждом цикле одно слово должно записаться, и одно-вычитаться.
Тут надо кропотливо поработать с таймингами ОЗУ.
Так получается тут нужно реализовывать конечный автомат состояний?
Проблема видимо в том что у меня два клоковых домина и я не соображу как мне преодалеть эту проблему. У меня есть основной клок в CPLD 100Mhz. Частота записи 50Mhz а частота чтения 10Mhz. Эти частоты я реализовал делителями.
Была идея:
Запись в абсолютном приоритете!! Если поступил запрос на чтение то мы ждём пока кончится запись и как только это произойдёт то мы прочитаем данные на выход и выставим флаг готовности данных, сбросив при этом флаги запроса. Но при таком раскладе у меня в RTL модели видны защёлки, а это явная ошибка проекта.
Как же быть?
Я просто чувствую что это вполне реализуемо, но нет идей и помощи более опытных товарищей. :laughing:
-
Удалось реализовать такой модуль FIFO на внешней SRAM, но работает он как то не стабильно и через раз!
Уважаемые спецы, помогите найти причины не стабильности.
module FIFO_SRAM( input Reset, input Wclk, input Rclk, input Rd, input Wd, output full, output empty, input [DATA-1:0] Din, output reg [DATA-1:0] Dout, output [ADDR-1:0] Addr_Sram, inout [DATA-1:0] Data_Sram, output nCS, output nOE, output nWE ); parameter ADDR = 4; // Параметр разрядности Адреса SRAM parameter DATA = 4; // Параметр разрядности Данных SRAM //--- Счётчики адресов чтения и записи ------------------------------ assign Addr_Sram = (Wd) ? write_addr[ADDR-1 : 0] : read_addr[ADDR-1 : 0]; reg [ADDR:0] read_addr=0; always @(posedge Rclk) //По такту чтения begin if(Reset) begin read_addr <= 0; end else begin if (Rd) read_addr <= read_addr + 1'b1; else read_addr <= read_addr; end end //--- reg [ADDR:0] write_addr=0; always @(posedge Wclk) //По такту записи begin if(Reset) begin write_addr <= 0; end else begin if (Wd) write_addr <= write_addr + 1'b1; else write_addr <= write_addr; end end //--- Абработка флагов заполненности ФИФО ------------------------------ assign full = ((write_addr[ADDR-1:0] == read_addr[ADDR-1:0]) && (write_addr[ADDR] ^ read_addr[ADDR]))? 1'b1 : 1'b0; //Фифо полное assign empty = ((write_addr[ADDR-1:0] == read_addr[ADDR-1:0]) && (!(write_addr[ADDR] ^ read_addr[ADDR])))? 1'b1 : 1'b0; //Фифо пустое //--- Логика комутации данных ------------------------------ wire [DATA-1 : 0] bus_data_out; always@(posedge Wd or posedge Rd) begin Dout <= bus_data_out; //При любом запросе пишим на выход end assign bus_data_out = (Wd & empty)? Din : 'bz ; //Если запись и фифо пустое то со входа пишем на прямую в выходной регистр assign Data_Sram = (Wd & ~empty)? Din : 'bz ; //Если запись и в выходном регистре не пусто то заполняем SRAM assign bus_data_out = (~Wd & Rd)? Data_Sram : 'bz ; //Если нет записи, но есть чтение то из SRAM в выходной регистр assign nCS = ~(Wd | Rd); //Разрешение чипа SRAM assign nOE = ~(Rd); //Чтение чипа SRAM assign nWE = ~(Wd); //Запись чипа SRAM endmodule
-
при старте, если указатели чтения и записи равны (т.е. записей в озу нет), то первая запись должна идти напрямую в dout.
empty при этом падает в 0.
следующие записи если empty в нуле идут в sram, счетчик записей увеличивается.
если активны циклы записи, а микроконтроллер увидев не empty решил почитать, то он читает dout, и empty становится в 1 до момента, когда будет возможность прочитать данные из sram в dout.
в ближайший возможный момент когда записи нет, а empty в 1, из sram вычитывается в dout, empty падает в 0.
идея понятна?
Оооо.. Точно!!!! Спасибо!!! Действительно в начале должны данные на выход захлопнутся, а уж потом сливаться в sram. Ведь если первым зашёл то первым и выйти должен по принципу фифо
Вобщем суть такая данные у меня заливаются в плис по 8 бит шине, а sram 16бит это дало мне возможность написать модуль который забирает данные по 8 бит и складывает в регистр 16 бит для того чтоб залить их в sram и плюс время целых два такта на то чтоб можно было по одному из них записывать, а по другому считывать.
Вот текст этой прослойки типа
module translator( input wire clk, //клок input wire [7:0]sbyte, //вход 1байт input wire rdy, //загрузка байта output reg [15:0]word, //выход 2байта output reg wr //данные готовы ); reg cnt = 0; reg [15:0]buff0 = 0; always @(posedge rdy) begin if(!cnt) begin buff0[15:8] = sbyte[7:0]; end else begin buff0[7:0] = sbyte[7:0]; word = buff0; end cnt = cnt + 1'b1; end always @(posedge clk) begin wr = ~cnt && rdy; end endmodule -
как я понял у ТС однопортовая память SRAM
Да! Одно портовая память срам! Хочу создать модуль контроллера срам, чтоб с ней работать как с фифо, но писать в неё по фронту сигнала WD который приходит из другого модуля, а по спаду WD сбрасывать в регистр и хранить там пока не перелью данные в мк и не произведу следующий запрос чтения.
Вот начал писать модуль сий. Затык с этим самым "автоматом состояний" который должен активировать регистр rdy когда посылаем запрос и ожидаем данные, вот тут за спотыкался.
module sram_control( input clk_pld, //основной такт плис input wd, //запись в sram, (высокий приоритет) input request, //запрос данных output reg ack, //подтверждение готовности данных output empty, //sram пустая (читать нельзя) output full, //sram полная (писать нельзя) output [17:0] addr, //адрес sram input [15:0] din, //вход данных для записи во внешнюю sram output reg [15:0] dout, //выход данных для чтения из sram inout [15:0] dinout //двунаправленный порт данных для подключения непосредственно к sram ); reg rdy = 0; reg [15:0] buff = 0; //буфер 3х состояний reg [18:0] count_w = 0; //регистр счётчика записи reg [18:0] count_r = 0; //регистр счётчика чтения //счётчик адреса записи always @(posedge clk) begin if(wd) count_w = count_w + 1; end //счётчик адреса чтения always @(posedge clk) begin if(rdу) count_r = count_r + 1; end //процес управляющий логикой чтения данных always @(posedge clk) begin if(request) begin //?????????????????????????????????? end end always @(posedge clk) begin if(wd) buff = din; else begin buff = 16'bz; if(rdу) dout = dinout; end end assign dinout = buff; assign addr = (!wd && rdу)? count_r : count_w; assign full = ((count_w[17:0] == count_r[17:0]) && (count_w[18] ^^ count_r[18]))? 1'b1 : 1'b0; assign empty = ((count_w[17:0] == count_r[17:0]) && (!(count_w[18] ^^ count_r[18])))? 1'b1 : 1'b0; endmodule -
Клока, клока... Я ж говорю что по импульсу от мк в плис плис должен зафиксировать факт прихода запроса на запись, дождатся этого самого вашего клока основного в плис и дождатся когда станет не активен сигнал записи из вне в срам и выгрузить байт из срам в регистр свой же и просигналить об этом мк что байт готов и находится в регистре вывода. При этом флаг запроса должен сбросится. Когда мы сново пошлём запрос байта для чтения этим самым сбросится флаг готовности байта.
Это что так сложно привести к основному клоку плис? Я только этого и не пойму в чём тут проблема то? Это что так сложно реализовать. Схема выше опасаной логики дана в первом посте. И вопрос - будет ли работать?
-
тактирование от АЦП есть всегда? оно на CPLD подано? хотелось бы прорегистрить сигналы от мк на частоте выдачи выборок АЦП. тогда проблема с синхронным дизайном решится сразу.
Ацп с мк никак не связаны! Плис управляет ацп по скрытому для мк алгаритму и записывает данные в срам нв хранение, мк же должно их оттуда забрать как только на это появится время. Места в срам полно, а ацп тактируется периодически по скрытому алгаритму. Просто хотел посоветоватся по возможности реализации псевдо фифо на связке срам+плис
-
я прошу прощения за мазню в paint, но это было быстрее всего.
я понял вашу задачу следующим образом.
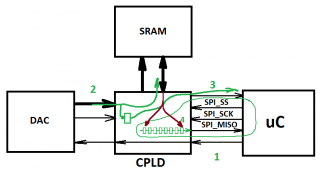
у вас есть АЦП и есть микроконтроллер.
но поскольку АЦП имеет скорость выдачи отсчетов выше, чем может принять мк, то было сгорожено CPLD и SRAM.
т.е. процесс примерно следющий
1) МК запускает выборку АЦП.
2) АЦП отсылает выборку в CPLD.
3) по мере передачи отсчетов от АЦП в SRAM в CPLD формируются счетчики уровня заполненности. wrptr-rdptr, сигналы fifo_empty, fifo_full, некий аналог usedw
4) при активации SPI со стороны мк вычитывается очередной байт данных. (ограничение - вычитывать из "фифо" можно только по 1 байту за каждую активацию SPI)
оно?
Да! Вы правы! Это то что я имел ввиду в общих чертах, с тем лишь отличием что плис сама загружает данные в срам и мк не как не воздействует на этот прцес! Мк лишь посылает запрос в плис на загрузку очередного байта в выходной spi буфер и как только это произойдёт то плис сигнализирует мк о готовности байта для передачи из плис в мк, а мк по spi выгружает байт к себе
-
волнуют возможности возникновения неопределенностей.
и соответственно исключение всяких граничных ситуаций.
меня не покидает ощущение, что вы хотите на них плюнуть/ махнуть рукой, и получившуюся конструкцию, которая может работать иногда продать за конструкцию, которая работает.
Не в коим разе не продаю ничего! Наоборот: Учусь, стараюсь сделать то что будет работать, и исключительно для познания, а не ради продаж!!!
практика показывает, что от 50% до 80% алгоритмов по объему - это обработка непредвиденных при нормальной работе ситуаций, и если вы ожидаете только тепличных условий по входным воздействиям - то это прямая дорога в адъ.Собственно для этого я и обратился к вам за помощью. Дельного посоветовали мало, но и не оскорбили никак и на том спасибо!!!
-
сколько за раз выгружается байт из озу в мк?
что, если посередине передачи по SPI возникла необходимость записи со стороны плис?
Тут всё просто мы отправили запрос с мк в плис и ждём ответа когда плис загрузит данные в регистр чтоб потом с помощью сдвигового регистра выгрузить байт из плис в мк. Скорость выгрузки соизмерима с ёмкостью этого псевдо-фифо. Что не понятно то я вот тоже не пойму проблемы что вас воснует в такого рода передачи.
что, если посередине передачи по SPI возникла необходимость записи со стороны плис?Этой проблемы не возникнет так как на время передачи из плис в мк запроса на чтение от мк не будет по понятным причинам и не что не потревожит плис загружать данные в срам.
-
Пожалуйста попытайтесь еще объяснить, что нужно сделать и требования.
И напишите все режимы/требования работы, а то у Вас в процессе общения появляются новые требования/режимы.
Для наглядности можете привести какие-то "картинки" схемы
Попытаюсь объяснить. Я с помощью плис захватываю данные с ацп на частоте клока плис 50mhz и пишу их во внешнюю sram. К плис подключен мк и по запросу плис должна загрузить в свой внутренний регистр данные которые читаем по принципу фифо, но только не важно какой там клок- просто послали с мк запрос на загрузку и как только это стало возможным в момент когда данные не записываются в срам, плис загружает данные в свой регистр. Сообщает об этом мк и мк с помощью сдвигового регистра как в интерфейсе SPI выгружает данные из плис к себе. Неужели не понятно объяснил?
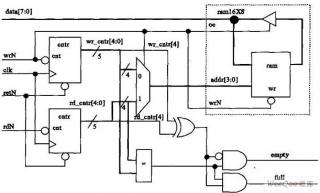
Вот картинка вдохновившая меня на реализацию этого "псевдо-фифо"
при записи одной ячейки озу одновременно и из мк и из плис - какой должен быть результат?Запись должна проходить с плис в срам! А вот если нет записи в срам но мк требует данные, то плис выгрузит из срам данные в свой внутренний регистр и сообщит об этом мк. - Как думаете это возможно?
-
тогда это не фифо, а озу с ручным управлением. назыавайте вещи своими именами.
один регистр - определяет к кому мультиплексорами подключена SRAM.
пишет этот регистр - всегда мк.
Запись в срам должна быть выше по приоритету чем чтение. Данных будет немного но быстро их пишем в срам, и если только мы не пишем в срам то есть возможность чтения
-
Тогда Вам в помощь одноклоковое фифо (памятью которого является сама SRAM) и логика приема, передачи данных.
PS Не уверен в корректности Вашей идеи...
Просто задача идеи состоит в том чтоб на высокой скорости загружать sram и потом по мере необходимости выгружать данные из sram. Но cpld уже есть EPM570 с подключенной к ней sram CY7C1041DV33. Почему б и не попробовать ведь ресурсов их хватает для задачи с головой. Просто криво возможно как то но возможно ведь?
-
Для двухклокового фифо нужна блочная память, т.е. FPGA, а не CPLD.
Мне не нужна двух клоковая фифо! Мне достаточно одного клока основного на стороне плис! Я лишь хочу с мк отправлять запрос на возможность запись во внутренний регистр плис данных и как только это станет возможным плис должна загрузить в свой регистр данные из срам и сообщить об этом факте мк.
-
И вообще как такое реализовать можно?
Я делаю так: Завожу 2 счетчика адреса (один для чтения другой для записи). По приходу сигнала на запись в срам счетчик адреса записи инкременирую +1 и записываю данные в срам. По приходу сигнала на загрузку в регистр данных для чтения я инкременирую +1 счетчик чтения и если значение счетчика чтения равно значению счётчика записи то фифо полное и запись не возможна, если же значение счётчика чтения меньше значения счётчика записи на -1 то фифо пустое и чтение запрещено!
-
Доброго времени суток уважаемые!!!
Есть задача построить модуль FIFO на связке CPLD+SRAM. Это образно говоря решение будет использоваться как простое FIFO для передачи данных в микроконтроллер. Мозги кипят и требуется помощь знающих людей которые смогут помочь разобраться в проблеме.
Вопрос коммутационного плана на выложенной схеме дело в том что мк и плис работают на разных тактовых частотах и тут то и проблема.
Я думаю так сделать:
Данные со входа IN_DATA[15..0] поступают во внешнюю sram и там фиксируются сигналом (wd_sram) по адресу схемы которая тут не представлена в принципе это не важно. Начало работы начинается с того что мк подаёт запрос на то чтоб данные записались в регистр (inst5) сигналом (request) и если sram находится в режиме чтения то данные записываются в регистр при этом выставляется флаг регистр загружен -(confirmation) и сбрасывается регистр запроса на запись данных из sram. По приходу следующего запроса записи из sram в регистр (inst5) флаг (confirmation) сбрасывается в ноль и мк ожидает загрузки регистра (inst5) из него потом сдвиговым регистром будут выгружены данные в мк. Так я предположил выйти из проблемы пересечения клоковых доменов асинхронной фифо. Подскажите в правильном ли я направлении двигаюсь?
-
Отписал в личку :rolleyes:
-
Пишите на [email protected] обсудим!
-
Измерять напряжение на выводах светодиода встроенным в мк ацп через резисторные делители и судить о свечении светодиода по падееию напряжения на нём.





Разработать блок питания 350мА 30-90В. Москва.
в Предлагаю работу
Опубликовано · Пожаловаться
Пишите на [email protected]
Обсудим!