


TU-104
-
Постов
76 -
Зарегистрирован
-
Посещение
Сообщения, опубликованные TU-104
-
-
Может, пошагово прерывания отключены, а в нормальном режиме срабатывают и вызывают фолт?
-
9 hours ago, Xenia said:
P.S. Платы "Blue Pill" предельно дешевы
Купить новых с десяток и не париться. Будет даже дешевле, чем контроллер покупать в чипдипе
-
20 hours ago, _4afc_ said:
Хотелось бы без закоротки посмотреть.
Вдруг LDO не может без большой ёмкости выдать ровное напряжение, а не PLL дурит без ёмкости на входе.
Вот
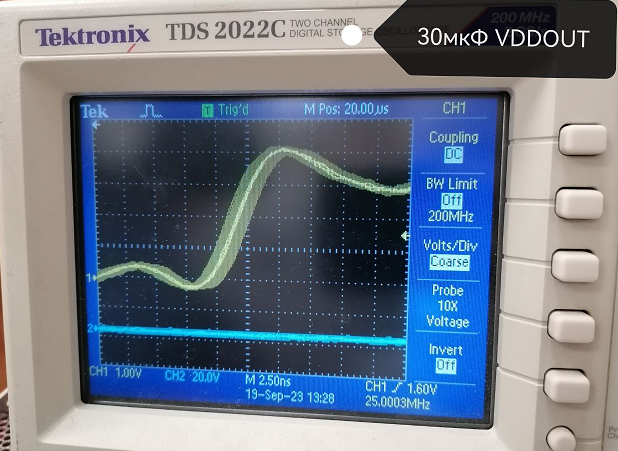
И ещё один вариант
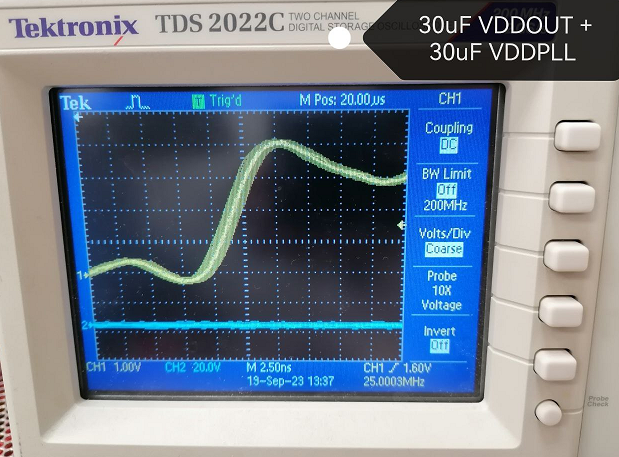
-
On 9/15/2023 at 9:14 PM, _4afc_ said:
Интересно как меняется эффект если по очереди (один из пунктов):
1. VDPLL добавить на С30 10-1000пФ NP0 (замкнуть ВЧ)
2. VDDOUT добавить на С36 30uF (замкнуть НЧ до BLM)
3. Закоротить BLM т.к. броски потребления тока переходят в пульсации напряжения из-за его сопротивления
1. Ничего вроде не поменялось
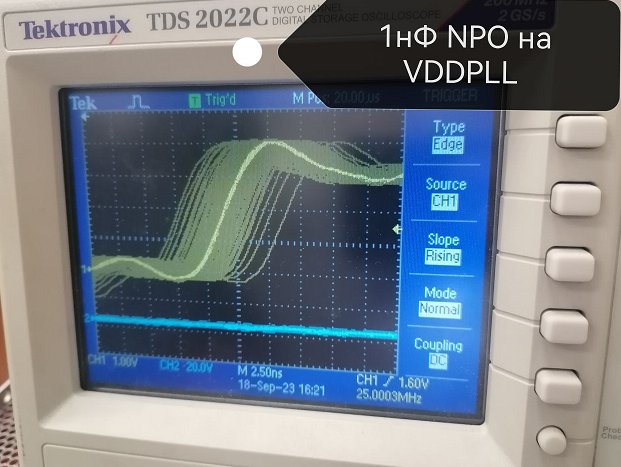
3. Что-то поменялось, немного "собраннее" что ли стал разброс, но все равно большой
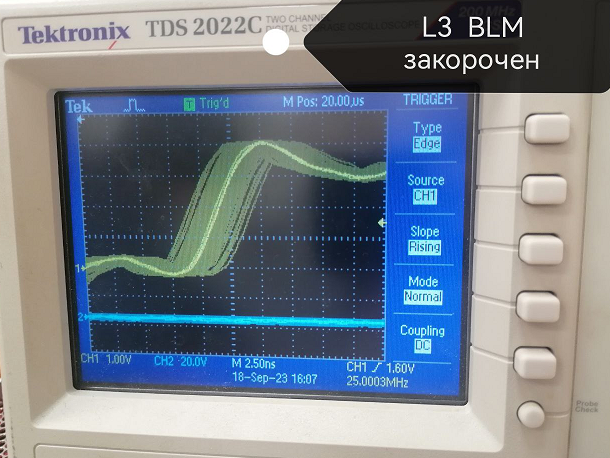
2(не совсем п.2). Пока L3 был закорочен, просто приложил большой электролит на VDDOUT
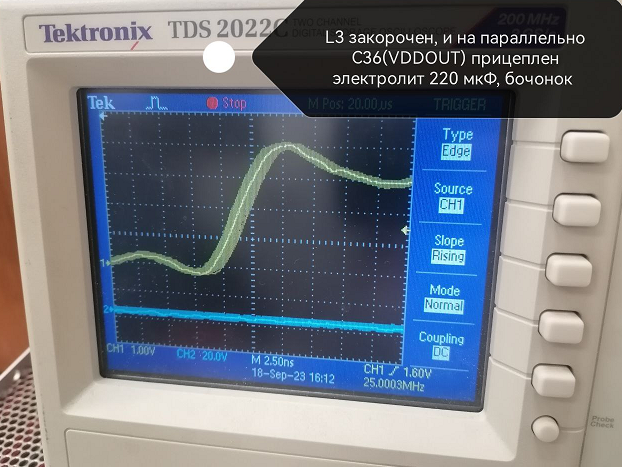
-
Опубликовано · Изменено пользователем TU-104 · Пожаловаться
3 hours ago, _4afc_ said:Какой тип L3 у вас и L201 на демо плате? На демо плате эффект есть?
Из спецификации демо: BLM18PG471SN1D 6 L200,L201.... Murata IND FER BEAD 470 OHM@100MHZ 1A 25% 0603
У нас то же самое (хотя на 100% не уверен, куплено по документам BLM18PG471SN1D ).
Демо-платы пока нет под рукойДа, на демо-плате такой же эффект

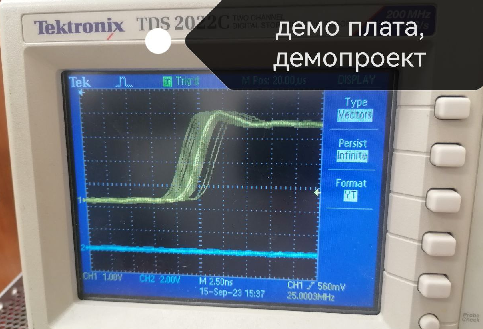
-
Вот этот же кусок с их демо-платы
Там как раз стоят X7R, X5R
C200, C201,C202..C214 921,C922 Murata CAP,100NF,+/-10%,X7R,16V,SMD0402
C215 YAGEO CAP,1UF,+/-10%,X5R,10V,SMD0402 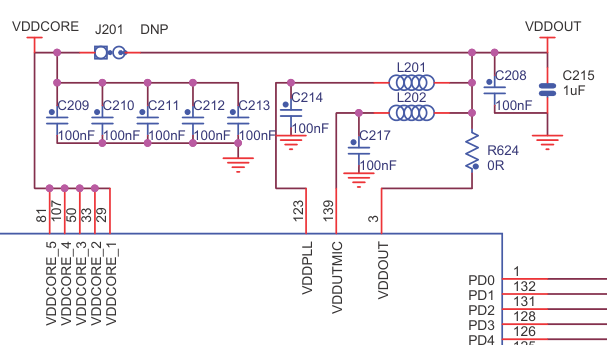
-
14 hours ago, Vasily_ said:
Значит надо LDO правильный применить ну и X5R ну тоже такое себе, да и тантал c низким ESR не мешает повесить.
Так LDO там встроенный (выход VDDOUT 1.2В), вот из даташита кусок
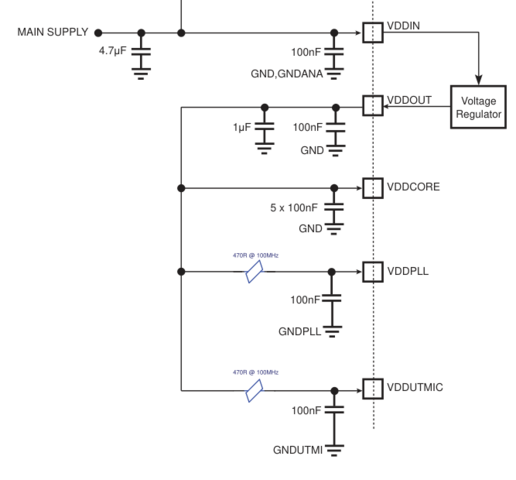
а что не так с X5R на столе в комнатных условиях?
-
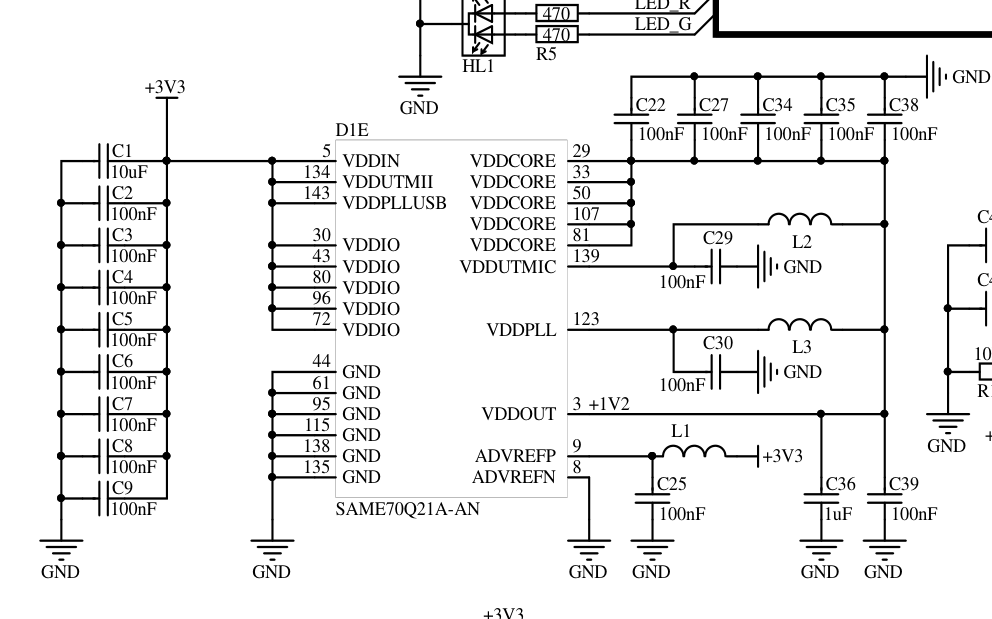
20 hours ago, Михась said:
Нестабильность питания PLL? Может на конденсаторы посмотреть на аналоговом домене?
Спасибо за наводку!
Выкладываю результаты.
Начальное состояние такое, измерял так ():
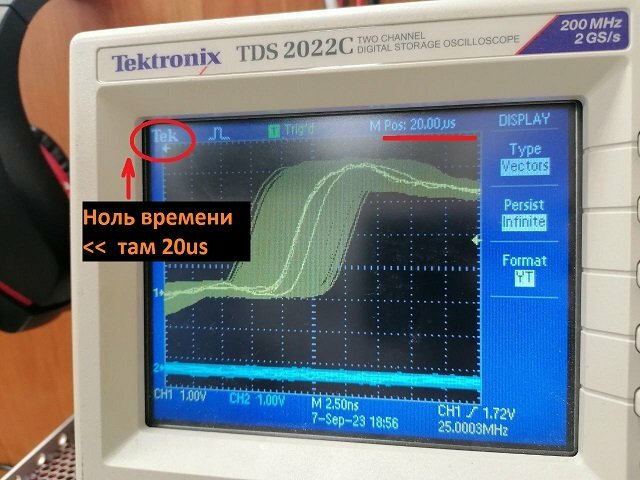
Дальше подписано, 10 мкФ на VDDOUT
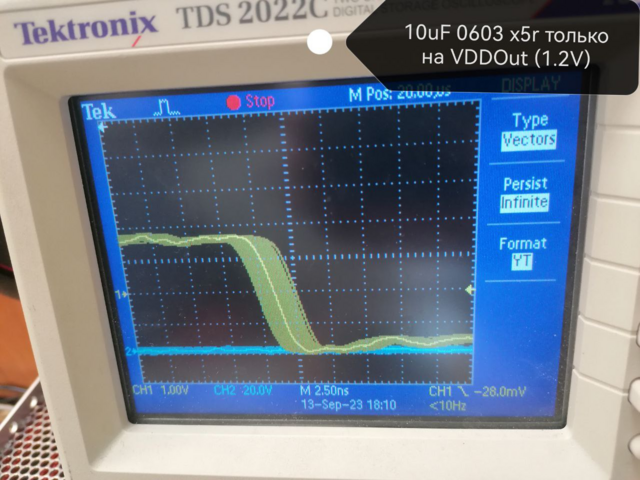
Лучший результат 30мкФ на VDDPLL
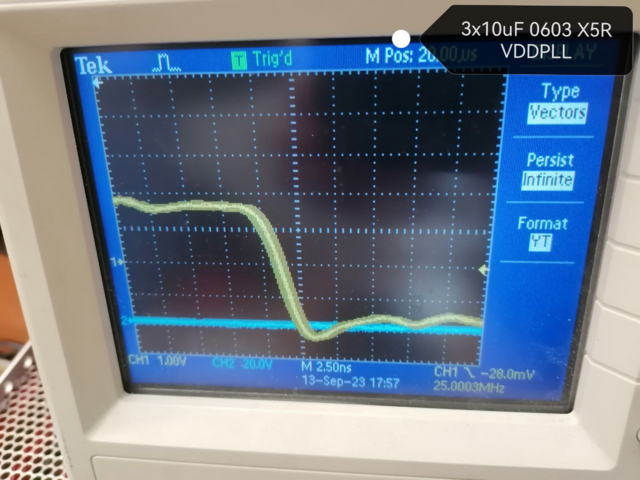
Но по даташиту и на демо-доске там только 0.1 мкФ. Вдруг оно(ядро или LDO) потом будет нестабильно запускаться?
-
Опубликовано · Изменено пользователем TU-104 · Пожаловаться
3 hours ago, Михась said:Нестабильность питания PLL? Может на конденсаторы посмотреть на аналоговом домене?
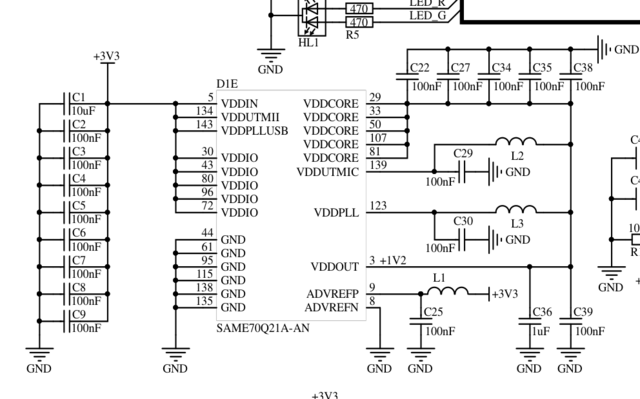
вроде как все выводы увешаны ими, примерно одинаково PLL|USBPLL. Даже usbpll без дросселя напрямую к +3.3В
Добавил 10uF X5R на VDDPLL, и правда стало лучше
-
On 9/7/2023 at 1:05 PM, TU-104 said:
SAME70. Кто-нибудь использовал в нём выход частоты из встроенной PLLA?
вообще всё - и прерывания и какой-либо код (не относящийся к работе с pll и с периферией портов). При этом с UPLL такого нет
Перепроверил всё ещё несколько раз - запустил демо-пример на двух платах.
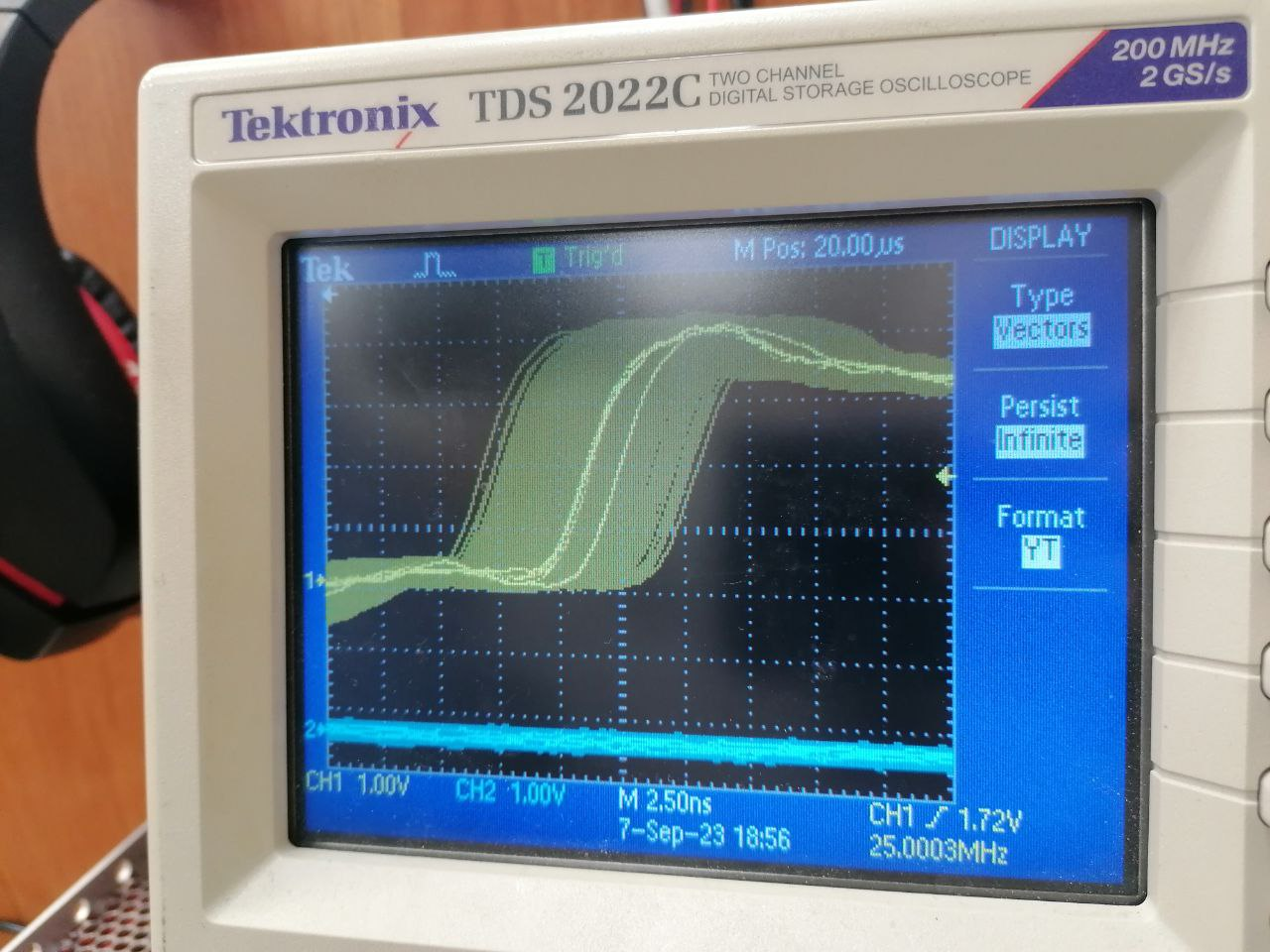
При выводе PLLA на пин - есть джиттер. При выводе UPLL - нету.
Если ядро отладчиком остановить - то частота на ножке стабильна.
Если ядро работает (в примере опрашивает регистр уарта, ждёт нажатия кнопки), то появляется такой вот "джиттер":
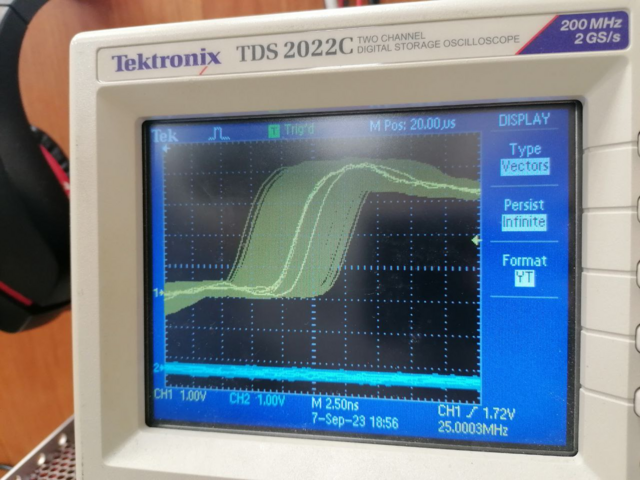
-
Опубликовано · Изменено пользователем TU-104 · Пожаловаться
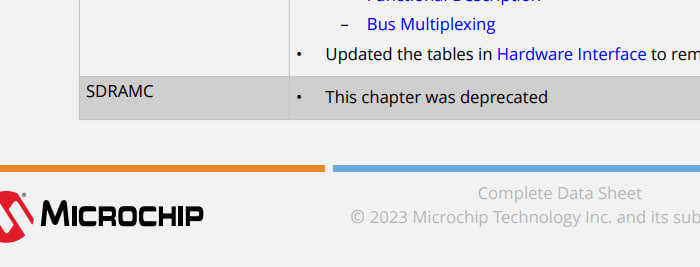
Ну и ещё добавлю новость: в новой еррате написано не использовать SDRAM. И на страничке рекламы и в новом даташите сдрам контроллера нет...

зато цветные колонтитулы добавили
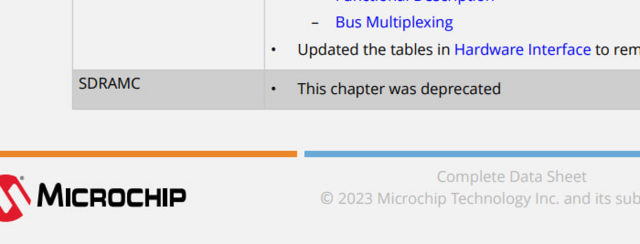
-
Опубликовано · Изменено пользователем TU-104 · Пожаловаться
SAME70. Кто-нибудь использовал в нём выход частоты из встроенной PLLA?
Почему-то у меня она получилась дёрганная и на это дёрганье как-то влияет FreeRTOS.
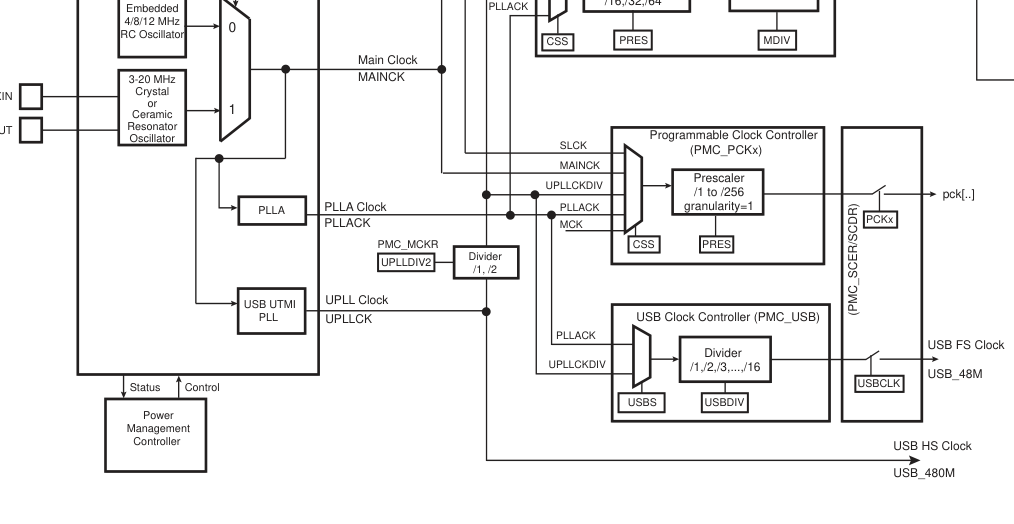
Вот такая картинка в даташите, можно любой клок выдать на три определённых ноги PCK_0..2
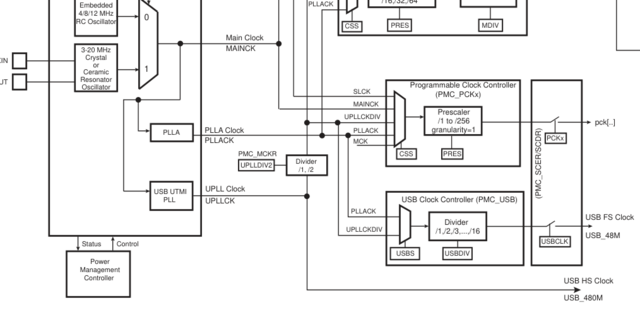
Включаю выход PCK_1, источник выбираю PLL, делитель на 12 (300/12=25МГц)
#define PIN_PCK_1 {PIO_PA17B_PCK1, PIOA, ID_PIOA, PIO_PERIPH_B, PIO_DEFAULT} PMC->PMC_SCDR = PMC_SCDR_PCK1; // disable PCK 1 while ((PMC->PMC_SCSR)& PMC_SCSR_PCK1); PMC->PMC_PCK[1] = PMC_PCK_PRES(11)| PMC_PCK_CSS_PLLA_CLK; //PMC_PCK_CSS_MCK; //; PMC->PMC_SCER = PMC_SCER_PCK1; while (!((PMC->PMC_SR) & PMC_SR_PCKRDY1));В пустом проекте всё красиво выводится, осциллограф в режиме запоминания показывает сдвиги меньше 1 нс
НО как только запускаю FreeRTOS, частота начинает "дёргаться" - фронты двигаются на +-5нс.
Пробовал убрать все задачи - дёрганья есть, т.е. не в моих задачах дело.
Пробовал в xPortSysTickHandler() поставить return - дёрганья пропадают.
Появляются где-то в этом 1мсек обработчике xPortSysTickHandler
portDISABLE_INTERRUPTS(); { /* Increment the RTOS tick. */ if( xTaskIncrementTick() != pdFALSE ) { /* A context switch is required. Context switching is performed in * the PendSV interrupt. Pend the PendSV interrupt. */ portNVIC_INT_CTRL_REG = portNVIC_PENDSVSET_BIT; } } portENABLE_INTERRUPTS(); }PS. Если выводить 24МГц на ту же ногу, но от источника UPLL, то никаких дёрганий нет
PPS убирал из этого обработчика по очереди всё что можно. Выяснил пока, что инструкции __DSB() ISB() в прерывании от СисТика "портят" частоту на ноге PCKxx. Как такое вообще может быть?
ppps. Выглядит, что на дёрганье частоты PLLA влияет вообще всё - и прерывания и какой-либо код (не относящийся к работе с pll и с периферией портов). При этом с UPLL такого нет
-
Опубликовано · Изменено пользователем TU-104 · Пожаловаться
PPS: Вот Си вариант, работает под cortex-M7 с float, под целые так и не переделал, не понадобилось
// буфер 240(30мс) s16 элементов накапливаю для обработки Герцелем// 3 цикла ДМА #define RX_DSP_LEN 240 // #define a1 :=2*cos(2*Pi*Ff/Fd); #define a1_1200 (float)1.1755705046 //1.1755705045849462583374119092781 #define a1_1600 (float)0.6180339888 //0.61803398874989484820458683436564 // вызывается из codec_work() при накоплении буфера 30мс void DSP_gertzel(){ s32 Summ = 0; s16 DCoff; u16 Amp; u32 i; float D0, D1, D2; float Amp12, Amp16; for (i=0;i<RX_DSP_LEN; i++){ Summ += Buf_DSP[i]; } DCoff = Summ/RX_DSP_LEN; // среднее арифм. DC offset Summ = 0; for (i=0;i<RX_DSP_LEN; i++){ Summ += abs(Buf_DSP[i]-DCoff); } Amp = (u16) round(((float)(Summ/RX_DSP_LEN)*PI/2)); // если общий уровень не в воротах, то просто считаю детекцию нулевой и выполняю что нужно if ((Amp<MIN_LVL_ADASE)||(Amp>MAX_LVL_ADASE)){ Amp12 = 0; Amp16 = 0; //d0printD(DEBUG_DSP, "\rDC=%d Amp=%d no proc xxx xxx ", DCoff, Amp); } else { // ******* сам алгоритм ********* // ********** 1200 ************** D1 = 0; D2 = 0; for (i=0; i<RX_DSP_LEN; i++){ D0 = Buf_DSP[i]+ a1_1200*D1-D2; D2 = D1; D1 = D0; } Amp12 = sqrt(D1*D1+D2*D2 - a1_1200*D1*D2); Amp12 = Amp12/(RX_DSP_LEN/2); // ********** 1600 ************ D1 = 0; D2 = 0; for (i=0; i<RX_DSP_LEN; i++){ D0 = Buf_DSP[i]+ a1_1600*D1-D2; D2 = D1; D1 = D0; } Amp16 = sqrt(D1*D1+D2*D2 - a1_1600*D1*D2); Amp16 = Amp16/(RX_DSP_LEN/2); // ******************************* } // Amp в норме // дальше определяем, какая частота присутствует. общий уровень отфильтрован выше if((Amp12 > MIN_LVL_ADASE)&&(Amp16> MIN_LVL_ADASE)){ (...) считаем на интервале 30мс обнаруженным } }
-
Опубликовано · Изменено пользователем TU-104 · Пожаловаться
7 hours ago, smk said:С изменениями разобрался. Всеравно не то. Пример бы рабочий.
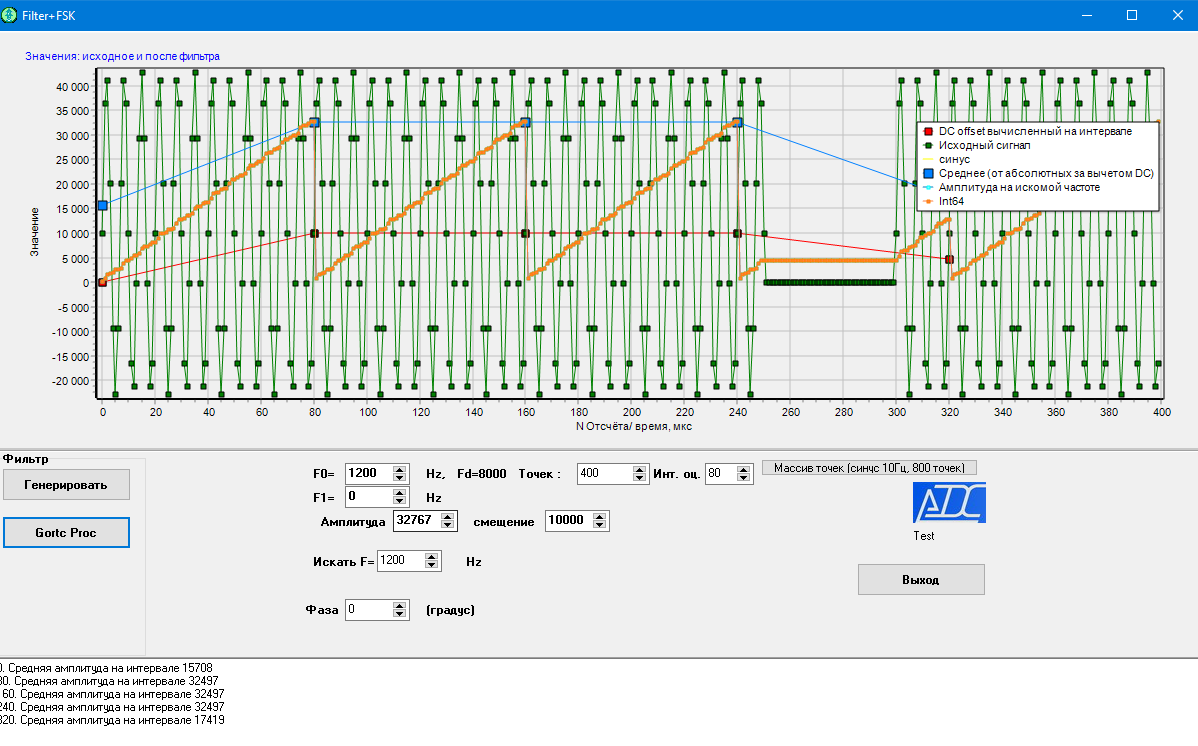
Вот рабочий пример, на паскале правда, возможно поможет, синтаксис там понятный.
Делал себе эмулятор когда-то, чтоб разобраться.
В программе можно сгенерировать 2 частоты F0+F1, чтоб посмотреть, как алгоритм отрабатывает на таких сигналах.
Для начала можно задать одну F0, тогда амплитуду F1 задать =0
Кнопка "Генерировать" - создаёт массив точек сгенерированного сигнала (число точек задаётся, Fs у меня всегда 8000 Гц) и выводит график.
Дальше задаётся длина интервала оценки, на которые будет разбит сигнал и на каждом будет запущен алгоритм Герцеля, задаётся искомая частота и нажимается кнопка "Gortc proc". Синим цветом у меня вычисляется амплитуда всего сигнала за вычетом DC на интервале, и при одной частоте видно как к концу интервала амплитуда равна числу, которое выдает алгоритм герцеля (он выдаёт амплитуду на искомой частоте)
Для сравнения еще сделано в целых числах, результат почти такой же точности(оранжевый график, он перекрывает бирюзовый)
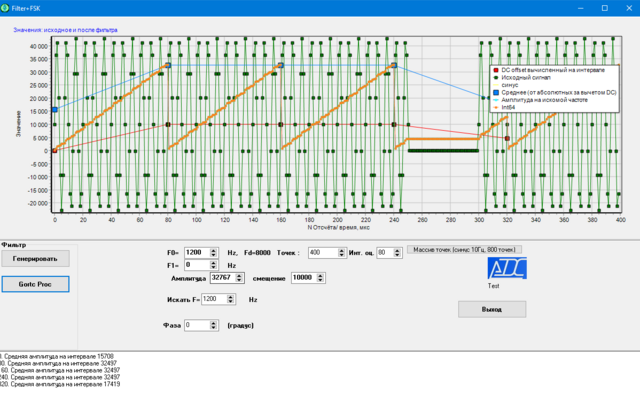
В архиве ехе-шник и .pas, часть нужного кода вставляю сюда:
Procedure Gortc_Proc(); //const a1 = 0.618; // 2•cos(2PI•k) k=f/Fd var D0, D1, D2 : real; iD0, iD1, iD2 : Int64; //integer; i : integer; P : real; Ff: integer; a1: real; iA1: Int64; NumSamples : integer; // число выборок для интервал оценки. с новым интервалом фильтр обнуляется begin Fmain.Chart1.Series[3].Clear; Fmain.Chart1.Series[4].Clear; Fmain.Chart1.Series[5].Clear; Ff := Fmain.SpinEditFfind.Value; a1 :=2*cos(2*Pi*Ff/Fd); NumSamples := Fmain.SpinEditInterval.Value; // D0 := 0; D1 := 0; D2 := 0; for i:= 0 to NumPoints-1 do begin D0 := X_IN[i]+ a1*D1-D2; D2 := D1; D1 := D0; P := sqrt(D1*D1+D2*D2 - a1*D1*D2); P := P/(NumSamples/2); // pp := round(P) div 10; Fmain.Chart1.Series[4].AddXY(i, P); // сброс коэффициентов через N мс if (i mod NumSamples) =0 // 80*125us = 10ms then begin mLog(IntToStr(i)+'. AMP(f) на интервале '+IntToStr(round(P))); D1:=0; D2:=0; end; end; //вариант с целыми iA1 := round(a1*256); iD1 := 0; iD2 := 0; for i:= 0 to NumPoints-1 do begin iD0 := X_IN[i]+ ((iA1*iD1) div 256) -iD2; iD2 := iD1; iD1 := iD0; P := sqrt(abs(iD1*iD1+iD2*iD2- iA1*iD1*iD2/256)); P := P/(NumSamples/2); // pp := round(P) div 10; Fmain.Chart1.Series[5].AddXY(i, P); // сброс коэффициентов через N мс с новым интервалом if (i mod NumSamples) =0 // 80*125us = 10ms then begin mLog(IntToStr(i)+'. AMP(f) на интервале '+IntToStr(round(P))); iD1:=0; iD2:=0; end; end; end;
PS. Наверно можно и в экселе сделать всё то же самое, скопировав формулы в сотню строк
-
Опубликовано · Изменено пользователем TU-104 · Пожаловаться
27 minutes ago, smk said:Как это использовать?
void SampleFilter_init(SampleFilter* f) { int i; for(i = 0; i < SAMPLEFILTER_TAP_NUM; ++i) f->history[i] = 0; f->last_index = 0; } void SampleFilter_put(SampleFilter* f, double input) { f->history[f->last_index++] = input; if(f->last_index == SAMPLEFILTER_TAP_NUM) f->last_index = 0; } double SampleFilter_get(SampleFilter* f) { double acc = 0; int index = f->last_index, i; for(i = 0; i < SAMPLEFILTER_TAP_NUM; ++i) { index = index != 0 ? index-1 : SAMPLEFILTER_TAP_NUM-1; acc += f->history[index] * filter_taps[i]; }; return acc; }Так всё же понятно:
- Завести переменную - структуру SampleFiler, передать её в начале в инит (там просто нулями заполняется массив сэмплов).
- Очередной сэмпл положить в массив функцией ..._put()
- Забрать c выхода фильтра тоже очередное значение .._get()
Но вам тут выше посоветовали для вашей задачи (обнаружение частоты) - быстрее Гертцелем
-
15 hours ago, Aleksandr Baranov said:
Есть довольно старый бесплатный пакет Winfilter. Можно попробовать его, если нет Матлаба.
Ещё онлайн есть такая штука http://t-filter.engineerjs.com , FIR мне понравился
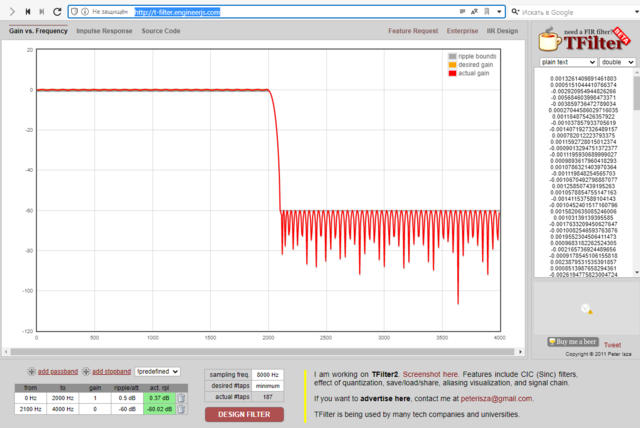
-
Тоже возник такой вопрос, в даташите на него ответа нет, в гугле только вот это для GD32F103CBT6 :
QuoteSRAM sizes are 32KiB in each largest block (128 KiB total) - stores code, which means first 128KiB could be accessed faster than typical flash. GD32 chips with 20Kb of SRAM or less have no more than 128KiB of flash, so all flash content is served from SRAM. This might also mean that startup time is slower than one would expect. With this SRAM mirroring it is not surprising that GD32 is beating STM32 in performance even on the same frequency and loosing in idle & sleep power consumption. Consumption at full load is lower than STM32 due to better (smaller) manufacturing technology.
Т.е. какое-то зеркалирование части флеш в SRAM
И ещё вот тут немного, говорят, что область кода с нулевой задержкой доступа:
QuoteAnd ST Different ,GD Of Flash There is the concept of partition , front 256K,CPU Execute instruction zero wait , call code District , Outside this scope is called dataZ District . There is no difference between the two in erasure operation , But there is a big difference in read operation time ,code The area code takes zero and waits ,data There is a large delay in executing code in the area , Code execution is more efficient than code The area is one order of magnitude slower , therefore data Areas usually do not recommend running code that requires high real-time performance , To solve this problem , The method of decentralized loading can be used , For example, put the initialization code , Picture code, etc data District .
И ещё документ "GD32 and STM32 Compatibility", тоже говорят про нулевые задержки в код-области и огромные в дата-области
QuoteGD32 flash consist of two areas: code area and data area. There is no difference in erasing and programing, but make difference in reading in two areas. Code area is zero wait for fetching instruction. Data area have a large delay in executing code. Thus, it is not recommend to run real time code solution Scatterloading, locate the real time code in flash code area;
-
Опубликовано · Изменено пользователем TU-104 · Пожаловаться
// если хочется, то можно передать указатель на свои аргументы XDMAD_SetCallback(&Dma, dmaSSC_RXch, (XdmadTransferCallback)SSC_Rx_Cb, NULL); XDMAD_SetCallback(&Dma, dmaSSC_TXch, (XdmadTransferCallback)SSC_Tx_Cb, NULL);
__________________________________________
// без доп аргументов *arg static void SSC_Tx_Cb(uint32_t channel) { //dPIN_OFF(PIN_TEST1); //d0print("SSCDMAcb tx ch:%u dmach:%u\n\r", channel, dmaSSC_TXch); // потом убрать это //NVIC_DisableIRQ(XDMAC_IRQn); XdmacChid * CHID = &(Dma.pXdmacs->XDMAC_CHID[dmaSSC_TXch]); u32 i; if ( (CHID->XDMAC_CNDA) == (u32)&LLIview0_TX[0] ) { pF_bufTX_rdy = &F_bufTX[0]; // в этот момент передаётся вторая часть буфера - по осциллу, и по выводу здесь } else //if ((CHID->XDMAC_CNDA) == (u32)&LLIview0_TX[1]) { pF_bufTX_rdy = &F_bufTX[FBTX_LEN/2]; }
Я сделал так, всё работает. (ps. same70)
-
Опубликовано · Изменено пользователем TU-104 · Пожаловаться
Пользуюсь проектом на основе примера atmel/lwip 1.3
Всё в общем-то работает (ip+udp), кроме случая когда данных в пакете UDP меньше 3(трёх) байт.
В регистре GMAC_DCFGR включаю бит GMAC_DCFGR_TXCOEN
QuoteTXCOEN: Transmitter Checksum Generation Offload Enable
Transmitter IP, TCP and UDP checksum generation offload enable. When set, the transmitter checksum generation engine
is enabled to calculate and substitute checksums for transmit frames. When clear, frame data is unaffectedЗатем формирую пакет udp для компьютера, отправляю, смотрю снифером (sam e70 >> PC )
Если в поле контрольной суммы в подготовленном на отправку пакете содержится не ноль (0х0000), то:
- для пакетов, в которых данных 3 байта и больше, контрольная сумма приходит правильная
- для пакетов, в которых данных 0,1,2 байта, контрольная сумма приходит 0xFFFF
Если в поле контрольной суммы в подготовленном на отправку пакете записать ноль (0х0000), то в приходящих на компьютер пакетах контрольная сумма ВСЕГДА правильная при любом количестве данных в UDP.
-
Опубликовано · Изменено пользователем TU-104 · Пожаловаться
- Может кто подскажет, а зачем сделаны 64-разрядными шины DTCM (2x32) и ITCM(64) ?
В его ассемблере (я не изучал) есть инструкции для загрузки 64-битных данных?
Посмотрел инструкции cortex-m7 по работе с памятью ADR/LDR - у них операнды 32-хразрядные. Если по этим шинам и так доступ без задержек, выполняется за 1 цикл, то зачем шина данных DTCM удвоенная? Как это можно использовать из Си-программы?
- Можно ли область ITCM использовать под данные? (К примеру, если не нужно переносить код в память, а itcm+dtcm включаются вместе)
-
Вдруг кому пригодится. Пользуюсь примером от Атмела gmac_lwip GMAC lwIP Example.
Включен аппаратный подсчет CRC на передачу и приём (биты GMAC_NCFGR_RXCOEN и GMAC_DCFGR_TXCOEN), программный подсчёт в lwip отключен.
При отправке пакета UDP необходимо поле UDP checksumm занулять.
Похоже, что МАС-контроллер пересчитывает её с учётом этих байтов, и если там уже лежит правильная сумма, то в пакет в эти поля вставляется FFFF.
При этом для TCP и для ICMP ничего подобного не наблюдается, для IP-header checksumm тоже.
Похожее же было и с STM32, но там нужно было занулять поля чексуммы только для icmp, остальные нормально считались.
-
1 hour ago, KnightIgor said:
Интересную вещь обнаружил.
Кто-нибудь встречал такое?
Встречал другое, в STM32_F_426 vgt(6 вроде) с размером флеш 1МБ
У него есть есть возможность выбора режима флеш: 1 банк 1 МБ, либо 2 банка х 512КБ
И это не просто логическое разделение 1х1МБ, либо 2х512, а действительно разные памяти флеш.
Как проверено:
- В режиме 1МБ заполнил флеш тестовыми данными
- Переключил режим на 512+512КБ
- Область №2 (вторые 512КБ) оказалась чистой (FF), заполнил и её
- Переключил обратно на режим 1МБ, в области №2 оказались старые данные из п.1
Т.е. получается памяти там 512КБ х3, и если нужно, то такими хитрыми извращениями можно что-то там хранить/спрятать
-
16 hours ago, dimka76 said:
Нестыковочка, однако )))
В прежних атмеловских ARM/Cortex был регистр Multi-driver Enable Register (PIO_MDER), который как раз для целей разрешения режима open-drain.
Ну и тут так же, из даташита на SamE70:

-
Когда надо было через несколько маршрутов отправлять, ничего не нагуглить не получилось.
Сделал "вручную": перед отправкой на конкретные адреса просто менял адрес шлюза netif_set_gw(...).
Вроде ничего криминального в этом нет: при первом отправляемом пакете будет арп-запрос на этот новый шлюз, затем в таблицу арп будет внесена запись вида IPd_st = MACaddr_GW. Ну и при последующих отправках, лишних запросов на шлюз не будет.
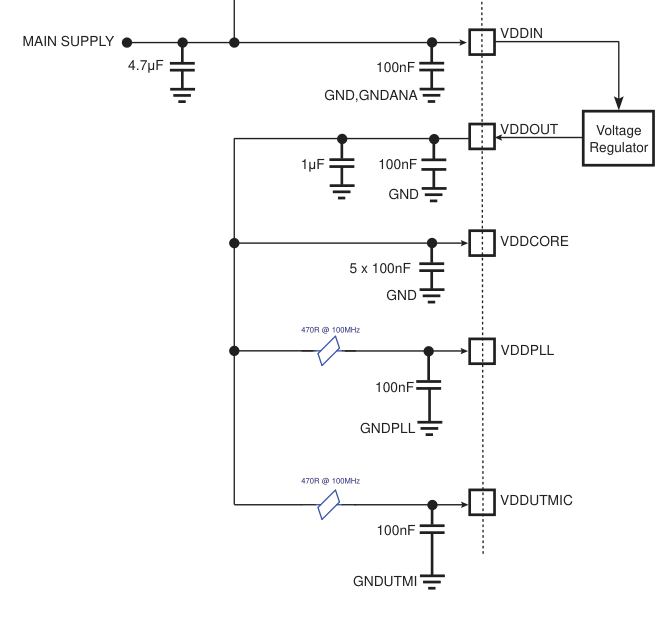
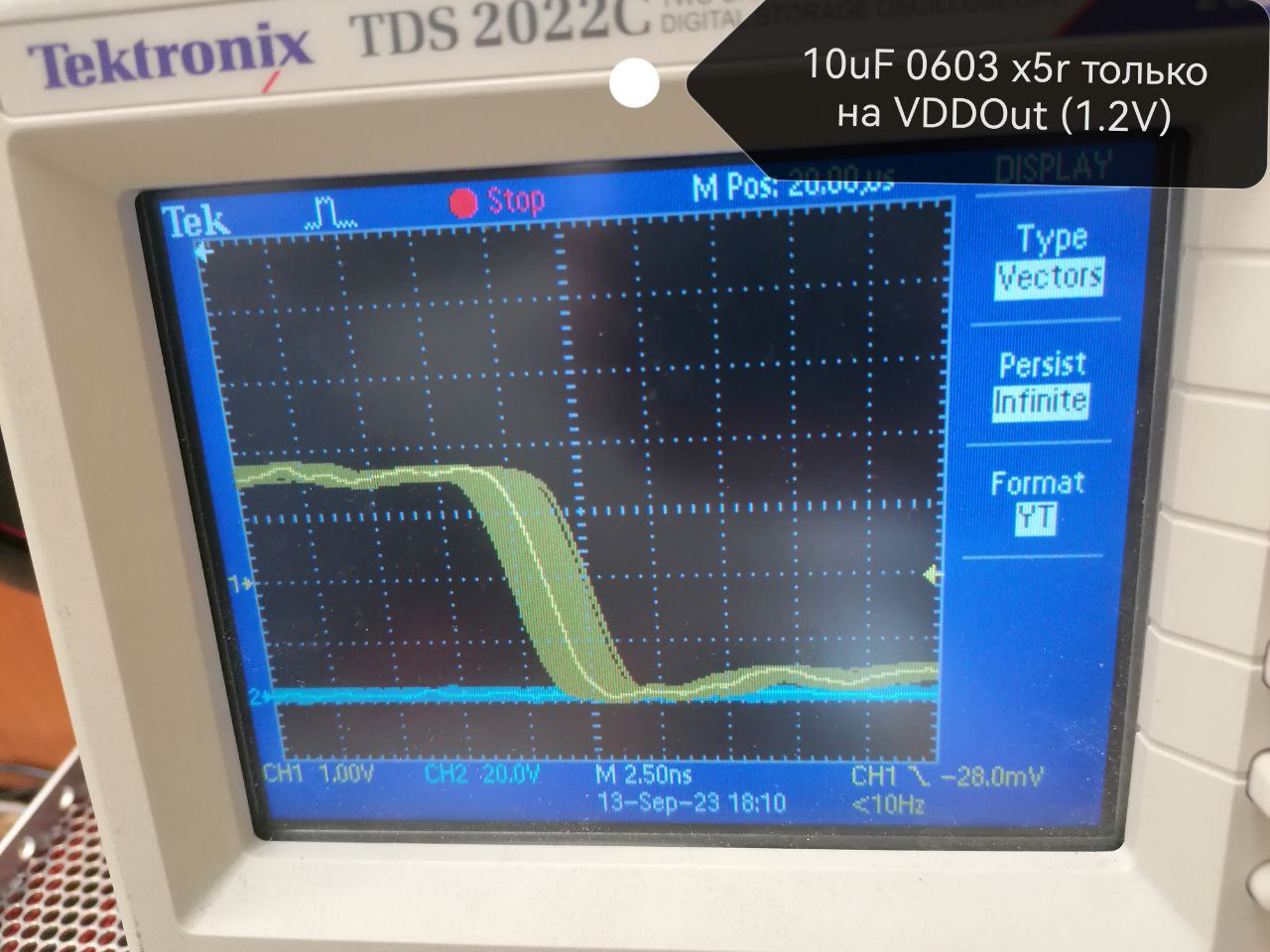
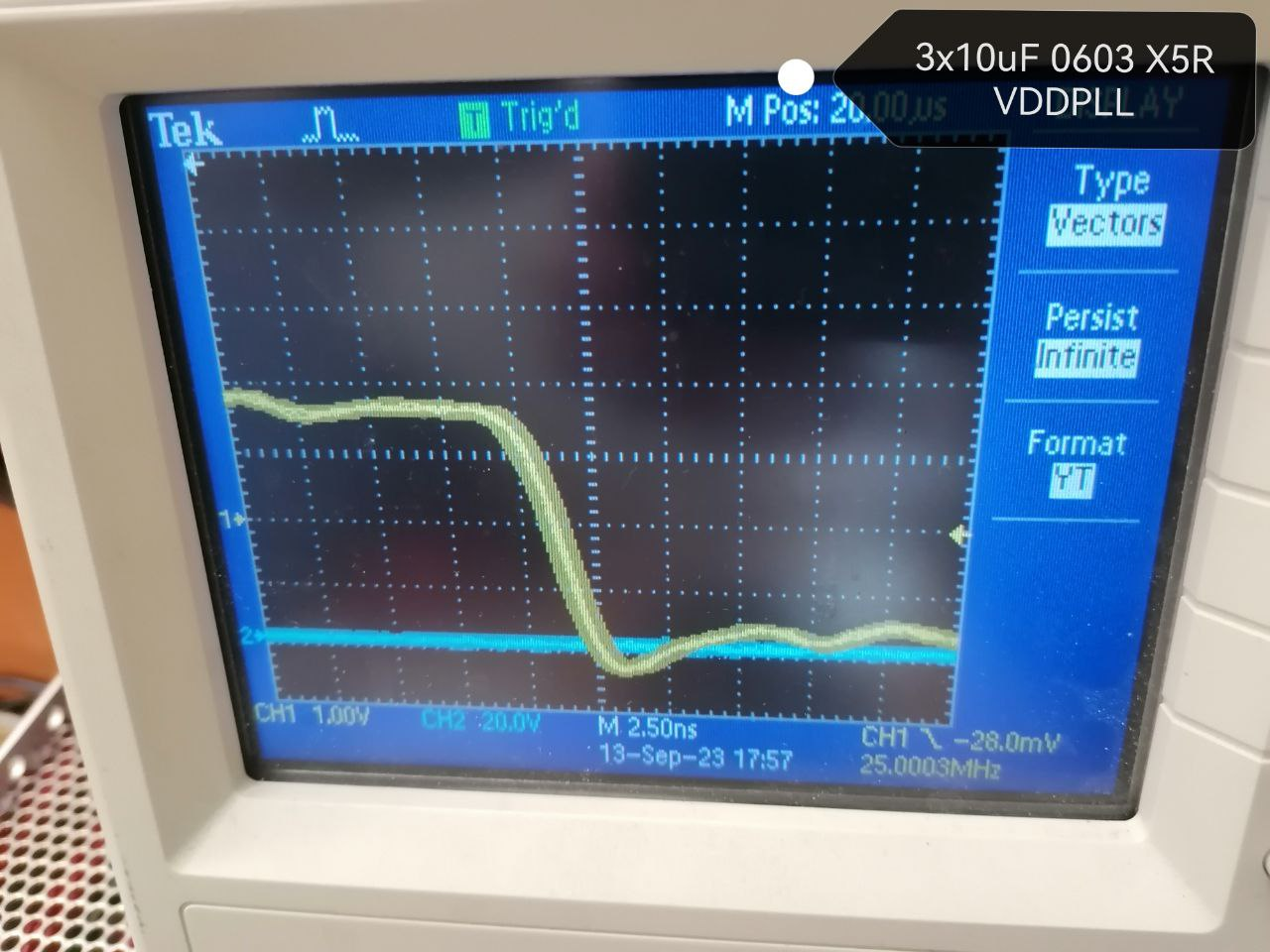



Microchip SAM E Series: обмен опытом
в Microchip (Atmel)
Опубликовано · Пожаловаться
А кто-нибудь использует в sam-e70 sdram контроллер и внешнюю память?
В новых даташитах вырезано всё, что связано с ней. Кто-то проверял новые чипы? Это только в документах вырезали, чтоб ошибки не исправлять или прям всё, кристалл переразвели.