repstosw
Участник-
Постов
2 694 -
Зарегистрирован
-
Победитель дней
2
Весь контент repstosw
-
Поздравляю с успешным запуском "гравицапы" ! :) У меня сейчас аналогичные дела - курю C6745, там тоже в большей части всё загадочно. Но курение даташитов + огрызки сорцов под CSL + ситары с бигл-бонами - делают своё дело! Нынче поколения эмбедеров пошло уже не то - Линуксы и кало-Кубы им подавай... Да, они словят "culture shock" от чтения мануалов, деградация поколений пошла. Я пока раскуривал мануалы на EDMA3 и McASP чуть мозг не свернул - реально потом нервы шалить стали (вынужден был на успокоительном сидеть), такая сильная увлеченность "excited"! )) Представляю что будет, если копнуть камень по-сложнее и с котороым полная задница в плане документации и примеров программирования (за минусом Линукса и ведра) - Alwinner A13, V3s :)))
-
Ну что, други! :))) Проблема успешно решена уже в третьей теме самостоятельно! Форум умер или вопрос теребует сверх-компетенции? Проблема была в силиконовой версии Run-time библиотеки. Надо ставить самую первую: rtspruv1_le.lib - с ней всё заработало. v2,v3 не идут с C6745. (rtspruv2_le.lib и rtspruv3_le.lib) Сравнил бинарные образы - да, различаются несколько байт. Вполне возможно что допустимо в поздних силиконовых ревизиях - недопустимо в первой. Для проверки работы PRU вот такой код использую: void delay(volatile unsigned int d) { while(d--); } void main(void) { delay(10000000); __halt(); } Что даёт задержку на доли секунды. Двоичный образ кода: #pragma DATA_ALIGN(PRU_CODE,4) const u8 PRU_CODE[0x1000]= { 0xc0, 0x00, 0x00, 0x24, 0x80, 0x80, 0x00, 0x24, 0xe2, 0xe0, 0x04, 0x05, 0xee, 0x00, 0x00, 0x24, 0xc3, 0x16, 0x00, 0x23, 0xee, 0x01, 0x00, 0x24, 0xc3, 0x1c, 0x00, 0x23, 0xe2, 0xe2, 0x04, 0x05, 0x8e, 0x22, 0x00, 0xe1, 0x80, 0x22, 0x00, 0xf1, 0xe0, 0xe0, 0x01, 0x05, 0x80, 0x22, 0x00, 0xe1, 0x00, 0x10, 0x00, 0x21, 0x80, 0x22, 0x00, 0xf1, 0xe0, 0xe0, 0x01, 0x05, 0x80, 0x22, 0x00, 0xe1, 0xc0, 0xff, 0xff, 0x24, 0x80, 0xff, 0xff, 0x24, 0x81, 0x22, 0x00, 0xf1, 0xfa, 0xe0, 0xe1, 0x6e, 0xe2, 0xe2, 0x04, 0x01, 0x00, 0x00, 0xc3, 0x20, 0x83, 0xc3, 0xc3, 0x10, 0xce, 0x98, 0x00, 0x24, 0x8e, 0x80, 0x96, 0x24, 0xc3, 0x07, 0x00, 0x23, 0x00, 0x00, 0x00, 0x2a, 0x00, 0x00, 0x83, 0x20, 0xc3, 0x1e, 0x00, 0x23, 0x00, 0x1d, 0x00, 0x21, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0xc3, 0x20, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, //....дальше нули };
-
C6745 и PRUSS
repstosw опубликовал тема в Сигнальные процессоры и их программирование - DSP
Запустил PRU0 в TMS320C6745, по крайней мере останавливается и считывает счётчик инструкции. Компилятор ti-cgt-pru_2.3.1 - виснет, падла в этом месте - когда программный счётчик =5: #pragma DATA_ALIGN(PRU_CODE,4) const u8 PRU_CODE[0x1000]= { 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xc0, 0x00, 0x00, 0x24, 0x80, 0x48, 0x00, 0x24, 0xe2, 0xe0, 0x04, 0x05, 0x8e, 0x81, 0xff, 0x2e, //5 => зависон 0xc3, 0x0d, 0x00, 0x23, 0xee, 0x01, 0x00, 0x24, 0xc3, 0x09, 0x00, 0x23, 0xc3, 0x0b, 0x00, 0x23, 0x00, 0x0a, 0x00, 0x21, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0xc3, 0x20, 0x00, 0x00, 0x00, 0x2a, //HALT 0x00, 0x0e, 0x00, 0x21, //Loop: goto Loop; Залез в MAP-файл, это подгаживает функция - _c_int00_noinit_noargs - до main() так и не доходит! Вот здесь виснет и не останавливается: 0x8e, 0x81, 0xff, 0x2e, //5 => зависон Сишный код самый простой что есть: void main(void) { __halt(); Loop: goto Loop; } Не выходит по останову - до Halt так и не добирается! Зато если сделать в самом начале оп-код halt: #pragma DATA_ALIGN(PRU_CODE,4) const u8 PRU_CODE[0x1000]= { 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x2a, //HALT То успешно останавливается и цикл в главной программе заканчивается: while(PRU0_CONTROL&(1<<15)) //if RUNSTATE=1 wait... Выходит компилятор C делает что-то недопустимое и он для ситар с бигл-бонами, но никак не для C6745 ??? PASM наше всё? Программный счетчик (там где в настоящий момент фетчится код) - смотрю в младших 16 битах регистра: PRU0_STATUS Вот тут ТП-Мелисса (других слов не нахожу) из TI так и не сумела объяснить причину зависона у аналогичного товарища: https://e2e.ti.com/support/processors/f/791/p/752634/2786060 Ну и до кучи привожу скрипт линковщика для PRU0: -cr /* LINK USING C CONVENTIONS */ /* -stack 0x8000 */ /* SOFTWARE STACK SIZE */ /* -heap 0x8000 */ /* HEAP AREA SIZE */ /* --args 0x100 */ /* SPECIFY THE SYSTEM MEMORY MAP */ MEMORY { PAGE 0: TEXT: org=0x00000008 len=0x00000FF8 PAGE 1: DATA: org=0x00000008 len=0x000001F8 } /* SPECIFY THE SECTIONS ALLOCATION INTO MEMORY */ SECTIONS { /* Forces _c_int00 to the start of PRU IRAM. Not necessary when loading an ELF file, but useful when loading a binary */ .text:_c_int00* : {} > 0x8 , PAGE 0 .text : {} > TEXT, PAGE 0 .stack : {} > DATA, PAGE 1 .bss : {} > DATA, PAGE 1 .cio : {} > DATA, PAGE 1 .data : {} > DATA, PAGE 1 palign=2 .switch : {} > DATA, PAGE 1 .sysmem : {} > DATA, PAGE 1 .cinit : {} > DATA, PAGE 1 .rodata : {} > DATA, PAGE 1 .rofardata : {} > DATA, PAGE 1 .farbss : {} > DATA, PAGE 1 .fardata : {} > DATA, PAGE 1 .resource_table : {} > DATA, PAGE 1 .init_array : {} > DATA, PAGE 1 .args : {} > DATA, PAGE 1 } Стек и куча задается в опциях линковщика - по 64 байта на каждый. А вот как бью эльфа(ELF) на 2 региона - код и данные: -b -image ROMS { PAGE 0: text: o=0x0, l=0x1000, files={text.bin} PAGE 1: data: o=0x0, l=0x0200, files={data.bin} } Но чего-то не фурычит как надо. Спецы, поможите!!! -
Проблема была успешно решена. Причина была в регистре DRAE1 его надо было включить. Только в этом случае прерывания от ДМА будут приходить (Event #8 по дефолту на INT8 в PINMUX2)
-
В C6745 выводил звук на DAC с помощью McASP + Audio FIFO + EDMA3. Претензий к качеству звука не имеется. McASP тактуется от кварца 24 МГц. Для борьбы с запаздываниями MCLK,BITCLK,FSYNC - правильно выбрать источники сигналов (всё брал относительно ноги MCLK) - иначе грязно будет играть. По идее, AUDIO FIFO должен обеспечить запас для непрерывности воспроизведения звука, в случае подгрузки данных по прерываниям или DMA в буфера. ADSP21489 имеет FIFO, DMA ?
-
Запустил EDMA3 в C6745 и программно проверяю конец передачи, чтобы не начать раньше следующую. Код: #define ACNT_MAX 65535 /* Если размер блока превышает это значение, то будет 2D DMA, иначе 1D DMA */ void EDMA3_Init(void *s,u32 n) { register u32 A=n,B=1; //1D DMA while(1) //2D DMA { if((A<=ACNT_MAX)&&(!(n%B)))break; B++; A=n/B; } EDMA3_ESR=0x00000000; //Channel 1 event clear EDMA3_ICR=0x00000001; //Channel 1 interrupt clear PaRAM_OPT=0; PaRAM_SRC=(u32)s; //SRC Address PaRAM_A_CNT=(u16)A; //1..65535 PaRAM_B_CNT=(u16)B; //1..65535 PaRAM_DST=LCD_D; //DST Address (LCD Data Port) PaRAM_SRC_BIDX=(u16)A; //-32786..32767 PaRAM_DST_BIDX=0; PaRAM_LINK=0xFFFF; PaRAM_BCNTRLD=0; PaRAM_SRC_CIDX=0; PaRAM_DST_CIDX=0; PaRAM_CCNT=1; PaRAM_RSVD=0; PaRAM_OPT=(1<<20)|(1<<3)|(1<<2)|(1<<1); //TCINTEN=1, STATIC=1, SYNCDIM=1, DAM=1 EDMA3_IESR=0x00000001; EDMA3_EESR=1; } Запуск ДМА: void EDMA3_Run(void) { EDMA3_ESR=0x00000001; //Channel 1 set } Программная проверка конца передачи: void EDMA_Wait(void) { while(!(EDMA3_IPR&0x00000001)); //Channel 1 interrupt pending EDMA3_ICR=0x00000001; //Channel 1 interrupt clear } Так всё работает. Но при поытке вызвать прервывание от EDMA3 - ничего не происходит, прерывание не вызывается. Код установки прерывания: void EDMA3_INT_Init(void) { INTMUX1=8; //Event #8 => INTSEL4 ISTP=(u32)_intcVectorTable; //set new Vector Table for Interrupt ICR=0xFFF0; //clear all interrupts, bits 4 thru 15 IER|=(1<<4)|(1<<1); //enable INT4, NMI interrupts _enable_interrupts(); } volatile u32 EDMA3_Flag=0; interrupt void EDMA3_INT(void) { LCD_Clear(0x0000); EDMA3_Flag=1; } Вектора: .align 1024 _intcVectorTable: _vector0: VEC_ENTRY _c_int00 ;RESET _vector1: VEC_ENTRY _vec_dummy ;NMI _vector2: VEC_ENTRY _vec_dummy ;RSVD _vector3: VEC_ENTRY _vec_dummy ;RSVD _vector4: VEC_ENTRY EDMA3_INT ;Interrupt4 ISR Ничерта не работает! Нет уверенности в том что на INTMUX сидит правильный номер эвента прерывания от EDMA. Даташит говорит что их целых 4: 8,56,57,58 - ни один не работает. Спецы, помогите, в чем может быть дело ?
-
Видео. Как-то так. Разрешение 400x240. Мигрировал на другой дисплей, более лучшего качества матрицы: https://www.youtube.com/watch?v=sBq2i1dVWh8
-
TMS320C6745 Выжал 88 кадров в секунду с реалтайм билинейной фильтрации. При этом формат пикселя 8:8:8 конвертится на лету в 5:6:5 и кидается DMA на дисплей. Всю программу и текстуру 128x128 32 bit per pixel - расположил в L2. Кеш 2 evtymibk c 256 кБ до 128 кБ. Во внешней SDRAM только 2 видеобуфера - один читает DMA в другой рендерит CPU. Без размещения текстуры во внутреней памяти было 80 кадров в секунду (зато кеш L2 в 2 раза больше доступен ) - +8 FPS прибавка . Долго не мог реализовать возврат дробной части вещественного числа - вначале делал так: _fabs(x - (float)_spint(x)) - была лажа местами из-за ошибок точности. Позже свой вариант написал - весьма заумный. Текст программы ниже - кадр 400 x 240 16 bpp - даёт 88 кадров в секунду с реал-тайм билинейной фильтрацией текстуры 128x128 32bit. union tc { u32 t; u8 c[4]; }; #pragma DATA_ALIGN(t0,4) union tc t0; #pragma DATA_ALIGN(t1,4) union tc t1; #pragma DATA_ALIGN(t2,4) union tc t2; #pragma DATA_ALIGN(t3,4) union tc t3; inline void Line(void) { register s32 a=_spint(x1); register s32 b=_spint(x2); //............... register u16 * restrict vb=(u16*)(SwitchBuffer[0]+(((y*MaxX)+a)<<1)); register u32 const * restrict pt=(u32 const*)TUNNEL; b-=a-1; _nassert(b>=2); #pragma MUST_ITERATE(2,,) do { register float rz=_rcpsp(z); register float p=u*rz; register float q=v*rz; register s32 sp=_spint(p); register s32 sq=_spint(q); register u32 a0=(( sp &(MaxU-1))*MaxU); register u32 a1=(((sp+1)&(MaxU-1))*MaxU); register u32 a2= ( sq &(MaxV-1)); register u32 a3= ((sq+1)&(MaxV-1)); t0.t=pt[a0+a2]; t1.t=pt[a0+a3]; t2.t=pt[a1+a2]; t3.t=pt[a1+a3]; *vb++=((_spint(MIX(MIX(t0.c[2],t2.c[2],p),MIX(t1.c[2],t3.c[2],p),q))&0xF8)<<8)| ((_spint(MIX(MIX(t0.c[1],t2.c[1],p),MIX(t1.c[1],t3.c[1],p),q))&0xFC)<<3)| ( _spint(MIX(MIX(t0.c[0],t2.c[0],p),MIX(t1.c[0],t3.c[0],p),q)) >>3); z=z+dz; u=u+du; v=v+dv; } while(--b); } Как бы ещё чего придумать чтоб быстрее было? И вот это можно написать более оптимальнее? Или может intrinsic есть? #define FRAC(t) (((float)(_spint(/*_fabsf*/(t)*256.0F)&0xFF))*0.00390625F) /* дробная часть : 256 градаций */ #define MIX(A,B,t) ((((B)-(A))*FRAC(t))+(A)) /* Интерполяция */
-
И снова здравствуйте! Реализую билинейную фильтрацию, алгоритм отладил. Теперь хочу перенести его на SIMD инструкции. Исходные цветовые компоненты хранятся в памяти так: 0:R:G:B= 8:8:8:8 бит Текстура 128x128 Необходимо в реальном времени считать билинейную фильтрацию. Работа с четыремя исходными пикселями. Алгоритм такой: #define FRAC(x) _fabsf((x)-((float)_spint(x))) /* Дробная часть. Есть ли intrising Для C6745 ??? */ #define MIX(A,B,t) (((t)*(B))+((1.0F-(t))*(A))) /* Интерполяция. Интрисинк есть??? */ //Тело цыкла: register float rz=_rcpsp(z); register float p=v*rz; register float q=u*rz; register s32 sp=_spint(p); register s32 sq=_spint(q); register s32 t00=pt[(( sp &(MaxU-1))*MaxU)+( sq &(MaxV-1))]; //исходные 4 пиксела в формате 0RGB по 8 бит каждый register s32 t01=pt[(( sp &(MaxU-1))*MaxU)+((sq+1)&(MaxV-1))]; register s32 t10=pt[(((sp+1)&(MaxU-1))*MaxU)+( sq &(MaxV-1))]; register s32 t11=pt[(((sp+1)&(MaxU-1))*MaxU)+((sq+1)&(MaxV-1))]; register float A=FRAC(p); register float B=FRAC(q); register float q0r; register float q0g; register float q0b; register float q1r; register float q1g; register float q1b; if(sp>0) { q0r=MIX((float)( t00>>16 ),(float)( t10>>16 ),A); //Покомпонентно интерполируем по X: top и bottom q0g=MIX((float)((t00>> 8)&0xFF),(float)((t10>> 8)&0xFF),A); q0b=MIX((float)( t00 &0xFF),(float)( t10 &0xFF),A); q1r=MIX((float)( t01>>16 ),(float)( t11>>16 ),A); q1g=MIX((float)((t01>> 8)&0xFF),(float)((t11>> 8)&0xFF),A); q1b=MIX((float)( t01 &0xFF),(float)( t11 &0xFF),A); } else { q0r=MIX((float)( t10>>16 ),(float)( t00>>16 ),A); q0g=MIX((float)((t10>> 8)&0xFF),(float)((t00>> 8)&0xFF),A); q0b=MIX((float)( t10 &0xFF),(float)( t00 &0xFF),A); q1r=MIX((float)( t11>>16 ),(float)( t01>>16 ),A); q1g=MIX((float)((t11>> 8)&0xFF),(float)((t01>> 8)&0xFF),A); q1b=MIX((float)( t11 &0xFF),(float)( t01 &0xFF),A); } register float q2r; register float q2g; register float q2b; if(sq>0) { q2r=MIX(q0r,q1r,B); //Покомпонентно интерполируем по Y q2g=MIX(q0g,q1g,B); q2b=MIX(q0b,q1b,B); } else { q2r=MIX(q1r,q0r,B); q2g=MIX(q1g,q0g,B); q2b=MIX(q1b,q0b,B); } *vb++=((_spint(q2r)&0xF8)<<8)|((_spint(q2g)&0xFC)<<3)|(_spint(q2b)>>3); //Собираем итоговый пиксел с конверсией 0:8:8:8 в 5:6:5 z=z+dz; u=u+du; v=v+dv; Есть ли интрисинки чтоб на SIMD переложить алгоритм для 6545-го ? Надо чтоб с 4 float работал (умножение сложение) и с 4 int ещё _x128_t для C6745 не поддерживается даже со включенным <c6x.h>
-
Протестировал ваш вариант. Даёт 183 кадра в секунду против 176 которые были. В ходе экспериментов выяснил, что если убрать из процедуры restrict и исключить: _nassert(b>=2); #pragma MUST_ITERATE(2,,) то будет 184 кадра в секунду. Быстродействие увеличено за счет отказа от 2-мерного массива и замена его на 1-мерный. Исходя из этого делаю предположение, либо что-то делаю не так, либо компиляторы поумнели. А вообще компилятор 8.3.3 сговнячился - растактовки да, не пишет. Прилагаю листинги и исходник что вышло t.rar.
-
Спасибо, как затестирую, результаты напишу! Это для разворота текстуры на 90 градусов Поотму что это не LST, а ASM. Могу сгенерировать LST - там растактовки есть
-
Да! Заинтересовали! :) 1) Может ещё эти замеры наведут на какие мысли: замерял скорость отрисовки чисто Туннеля - 215 за секунду. И столько же раз как это ни странно рисует DMA отдельно. А вот вместе свего 176 раз. Скорее всего из-за обращения к внешней памяти - туда CPU строит один буфер, а DMA забирает оттуда другой. Ещё укоротил кеш L2 в 2 раза: был 256 кБ, сделал 128 кБ. Секцию .text(код программы) и .stack толкнул в освобожденную L2. ФПС понизился с 176 до 154 . Тоесть стало хуже. 2) Может разделить буфера на банки ? Один в одной банке SDRAM, второй - в другой, или ничего полезного не будет? 3) Ещё в функциях текстурирования много однотипных вычислений типа сложение-умножение по координатам X,Y,Z и по текстурным U,V. Применение SIMD напрашивается.
-
Так в проекте в Release сгенерированные asm-файлы! Прикладываю main.asm. Если возможно, можете взглянуть и проанализировать его? 90% уверен что код неоптимален! Сгенеренный asm. По-моему он лучше, чем lst: main.asm
-
Использую DMA. Рестрикты не используются так как не CPU. На счет параллельности, управляющий код - не задача ЦОС, поэтому покласть его на конвеер будет ох как проблематично. Есть принцип Паретто: если 20% усилий приводят к 80% результа - это хорошее усилие. А если 80% усилий привели к 20% результата - это становится неэффективным. Основной тормоз был - наличие двух делений в текстурных координатах во внутреннем цикле отрисовки линии. Заменив их на умножение с 1/x, получил сразу колоссальный прирост. Избавление от остальных делений в прочих участках кода - принесли уже менее ощутимые приросты. ))
-
Как я уже писал тут: https://electronix.ru/forum/index.php?app=forums&module=forums&controller=topic&id=151163 отрисовка кадра 480x320 через DMA в чистом виде идёт со скоростью 98 кадров в секунду. Не забываем что код и данные во внешней памяти SDRAM. Алгоритм построения одного фрейма Туннеля занимает больше времени, чем отрисовка DMA, это видно из того , что с Туннелем 89 кадров в секунду и DMA параллелен. Дисплей висит на EMIFA, память на EMIFB. О каких конфликтах на шине речь? В принципе результатом я доволен. Можно получить выше, но прийдётся вылизывать код рендеринга Туннеля. Исходники выложил, кому интересно - прошу совершенствовать ))) Отображение географии в 3D для МинОбороны - мониторинг зоны боевых действий. Не всегда можно Epson или Crimson поставить ))) Шутка, чисто академический интерес, сравнить C6745 , BF532 и STM32
-
Видео туннеля в действии после частичной оптимизации. 320x240, текстура 512x512 : https://www.youtube.com/watch?v=8xuzbmDLAnM => 129 кадров в секунду 480x320, текстура 512x512: https://www.youtube.com/watch?v=NzSa0Sfdjyc => 89 кадров в секунду Исходники туннеля (проект полностью, отрисовка через DMA): Tunnel_C6745.zip Удивительно, но факт! У STM32 вся память была на 400 МГц и SRAM с 1 тактовым доступом, у C6745 внешняя SDRAM с доступом несколько тактов и быстрее )) Наверное из-за архитектуры VLIW + кеши 32+32+256 кБ против 16+16 у STM
-
Нашёл причину "рассыпания" текстур. При движении текстурная координата неумолимо росла до больших величин, что сказалось на потере точности. Было так: float J1=MaxV-((MaxV*((float) j ))/P2)-(Angle*TEXTURE_SPEED); float J2=MaxV-((MaxV*((float)(j+1)))/P2)-(Angle*TEXTURE_SPEED); Стало так: s32 move=MaxV-(((s32)(Angle*TEXTURE_SPEED))&(MaxV-1)); float J1=move-((MaxV* j )/P2); float J2=move-((MaxV*(j+1))/P2); Теперь всё нормально! Увеличило скорость отрисовки на 5%, что хорошо. Итого кадр 320x240 16 бит на точку , текстура 128x128 - тянет 176 кадров в секунду - с параллельной отрисовкой с помощью DMA. С STM32H743 результат был в 2 раза меньше! Хотя тоже DMA и память внутренняя на частоте ядра. STM32 курит в сторонке ?
-
OK, спасибо! Попутно новая проблема вылезла: В цикле отрисовки линии : while(b--) { FLOAT rz=_rcpsp(z); *vb++=(*Texture)[TRUNC(v*rz)&(MaxV-1)][TRUNC(u*rz)&(MaxU-1)]; z=z+dz; u=u+du; v=v+dv; } Со временем текстура деградирует - становится дырявой. В то время когда прежний код, который медлительный из-за делений: while(b--) { *vb++=(*Texture)[TRUNC(v/z)&(MaxV-1)][TRUNC(u/z)&(MaxU-1)]; z=z+dz; u=u+du; v=v+dv; } работает без деградации текстуры. Выходит что умножение на обратную величину приводит к потери точности, так как текстурные координаты постепенно "сползают" и картинка со временем становится дырявой. Что можно предпринять в этом случае?
-
Спасибо огромное! Да, заменил деление везде на умножение на интринсик _rcpsp() - тормоза исчезли, всё идёт очень лихо! Было 67 делений в программе. Часть из них сидели в цикле отрисовки линий. Попутно спрошу, есть ли возможность поменять местами значения переменных, а то приходится писать что-то вроде такого: if(p0y>p1y) { templ=p0y; p0y=p1y; p1y=templ; Весь код (начальный, без оптимизации) - привожу ниже. Рисуем текстуры.... На STM32H743 этот код просто летает.
-
Неужели это деление тоже через интринсики надо писать? Очень неудобно. В том же Keil + STM32 с их поддержкой VFPv4 плавучка инлайнится напрямую без применения интринсиков..
-
Это мне понятно. Непонятно, как заставить инлайниться во floating-point такой кусок кода: float A=0.4F; float B=0.223424F; float C; void main(void) { C=A/B; } Это простое деление, и оно должно инлайниться в инструкции , а не через CALL вызываться.
-
C6745 и floating point
repstosw опубликовал тема в Сигнальные процессоры и их программирование - DSP
Делаю расчёты в формате floating point. К примеру - делю одно на другое. В асм-листинге вижу такое: $C$RL64: ; CALL OCCURS {__c6xabi_divf} {0} ; [] |147| ;** --------------------------------------------------------------------------* CALLP .S2 __c6xabi_divf,B3 ; [B_Sb674] |147| Как это безобразие называется??? Аппаратная поддержка floating point? C6745 вообще поддерживает операции с плавающей точкой или нет? Я ожидал инлайнинга иструкций на ассемблере, а не вызов функций с черт-пойми каким содержимым. Как итог: программа тормозит, и скорее всего там идёт целочисленная эмуляция плавучки. Спецы, подскажите, как заставить генериться код с ассемблерными инструкциями плавучки? -
C6745 и SPI для SD-карты.
repstosw опубликовал тема в Сигнальные процессоры и их программирование - DSP
Настроил шину SPI для взаимодействия с SD-картой. Частота ядра - 456 МГц Максимальный делитель для тактовой частоты SPI - 256, что даёт : SYS_CLK2/256 = (456/2) / (255+1) = 890 кГц А для инита SD карты надо 400 кГц. Можно ли без изменения настроек PLL изменить временно SYS_CLK2 так, чтобы тактовая частота SPI была 400 кГц или ниже? Есть ли возможность затактировать SPI модуль не от SYS_CLK2, а от XTAL=24 МГц ? SPI0 не предлагать, на нём висит Boot EEPROM. -
Про рестрикты почитал. Не годятся для моих целей, так как регион памяти используется в других функциях - например своппинг байтов в словах. Тоже указатель. Пользуясь случаем, как раз на счёт свопинга спрошу, можно ли в настройках EDMA указать чтобы байты менялись местами - старший с младшим ? Когда шина дисплея 8 бит, а передача идёт 16- 32- и 64- разрядными словами, то DMA передаёт вначале старший байт, а надо младший! (иначе цвет точек некорректный) В STM32H743 такая возможность есть. Есть ли в C6745 ? P.S. при первом наборе постов не сохраняется форматирование, приходится редактировать. Движок форума можно пофиксить?
-
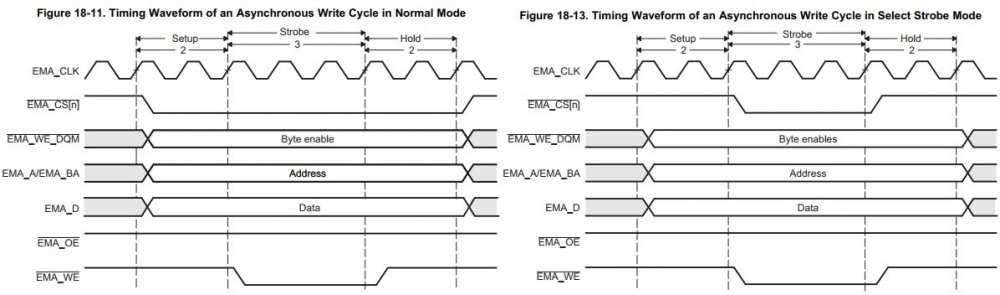
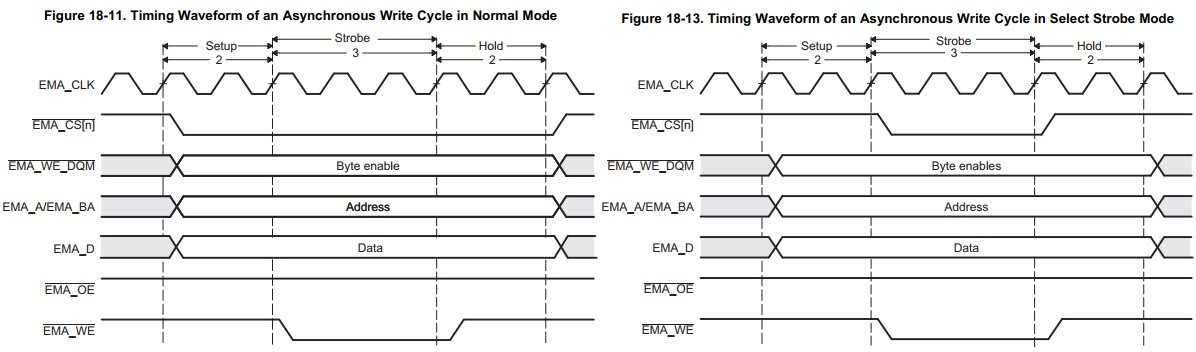
Немного повысил скорость путём изменения режима работы EMIFA, выбран Strobe Mode вместо Normal Mode, тем самым, Write Strobe Width стало возможным укоротить без нарушения работы LCD: EMIFA_CE2CFG= (1<<31)| //Select Strobe (0 - Normal Mode) (0<<30)| //Extend Wait (0 - disabled) (0<<26)| //Write setup width 0..15 (0 - EMA_CLK/1) (0<<20)| //Write strobe width 0..63 (0 - EMA_CLK/1) (0<<17)| //Write hold width 0..7 (0 - EMA_CLK/1) (0<<13)| //Read setup width 0..15 (0 - EMA_CLK/1) (0<< 7)| //Read strobe width 0..63 (0 - EMA_CLK/1) (0<< 4)| //Read hold width 0..7 (0 - EMA_CLK/1) (0<< 2)| //Minimum Turn-Around time (min. num. of EMA_CLK cycles between reads & writes - 1) 0 ; //Asynchronous Data Bus Width (0 - 8 bit) Теперь так: 91 кадров в секунду - CPU 98 кадров в секунду - DMA Режимы(выбран вариант справа): А вот тут 60 FPS через SPI и площадь экрана в 2 раза меньше: https://retropie.org.uk/forum/topic/14519/fast-refresh-rates-up-to-60fps-with-an-spi-display-ili9341