Вадим Н.
-
Постов
31 -
Зарегистрирован
-
Посещение
Информация о Вадим Н.
-
Звание
Участник
")
-
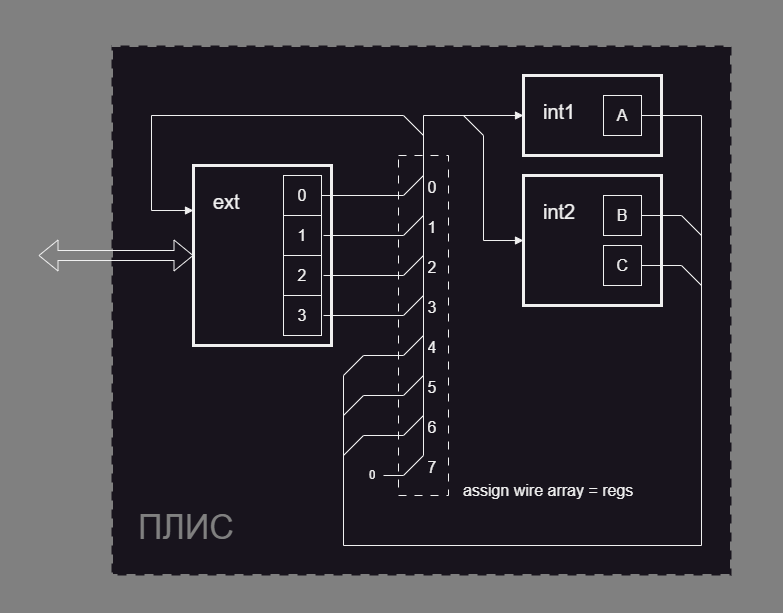
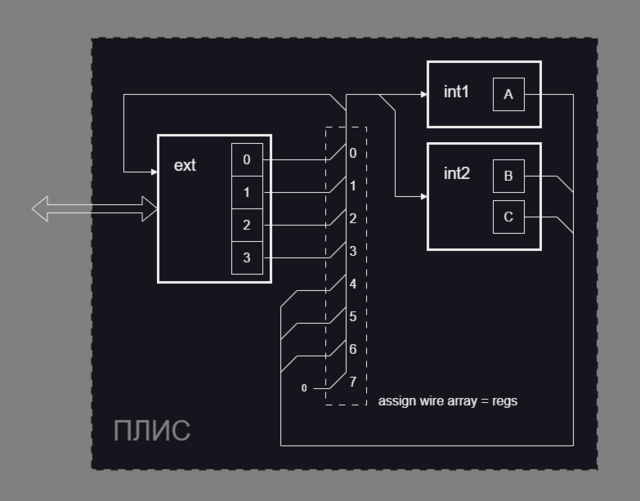
вот прототип. не сказать, что это прям концепт-пруф. не могу понять, почему не проходит тест под iverilog хотя под Modelsim вроде бы норм. собирается под quartus и gowin. В обоих случаях занимает примерно одинаковое число д-триггеров. Число не сильно отличается от <число бит в слове> ** 2 * <число бит в шине адреса> - <не используемая часть см. gen_notused.v> SRAM-память, понятно, не выводится из такого описания. идея в целом такая: каждый модуль пишет в регистры объявленные локально а читает из вот этой вот конструкции которая массив wire память из этого не выводится при синтезе, так как чтение может идти параллельно см. блок схему: не уверен что этого достаточно чтобы однозначно сделать выбор в пользу такой схемы а не нормальной памяти. Подкупает возможность произвольно читать регистры. и не морочиться в каждом модуле-читателе с интерфейсом к SRAM. Минусы такие что 1. можно упереться в ресурсы и потом всё же придётся переписывать всё с нормальным доступом к SRAM. 2. может в реальных условиях эта схема вообще не заработает. а ещё будет смешно если окажется что обмен с памятью операция на столько простая что вообще нечего было разводить вот это всё. М.б. сделаю ещё примерчик пригодный для заливки на макетку вот такую. test_conf.7z
-
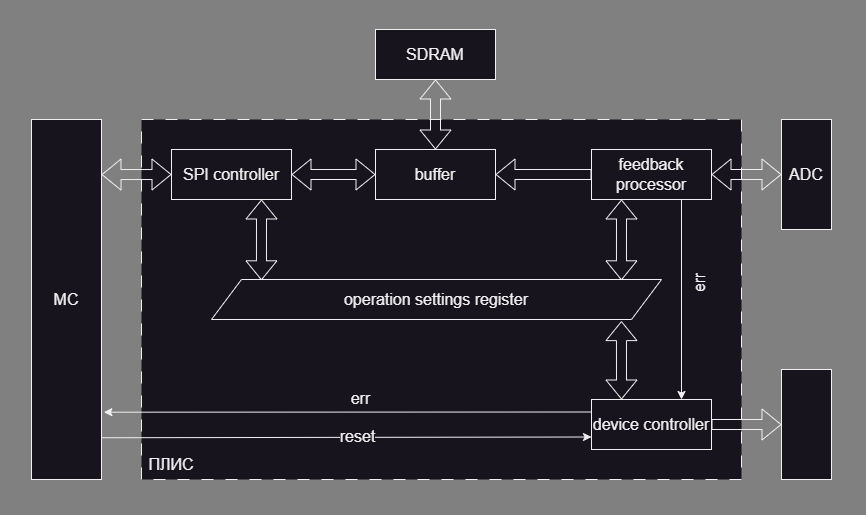
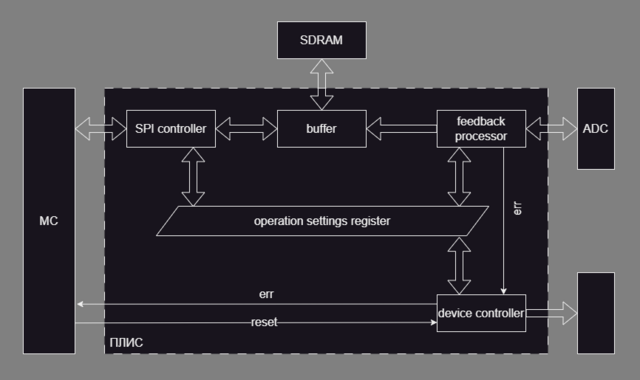
Всем привет, У меня задача: запрограммировать на GW2A18 определённый алгоритм управления устройством с обратной связью. У кого есть опыт проектирования чего-то подобного, посмотрите пожалуйста. Термины и названия блоков навеяны одной презентацией GoWin. См. скрин: Надо сказать, что первая версия "дизайна" толком не работала, и блок-схема, нарисованная уже постфактум, (я её здесь не привожу) похожа на кашу из модулей. По новой блок-схеме есть сомнения и вопросы: "Буфер" - это модуль который накапливает актуальную телеметрию на случай если она понадобится для отправки по SPI. Как он реализуется я пока не знаю. "Регистр настроек работы" - это вот главный вопрос. Вообще-то это массив. Где-нибудь 16x64. Не пойму: это должно быть реализовано как память, или можно реализовать и доступ по адресу, и непосредственный доступ к отдельным регистрам для параллельного чтения/записи. Вот сценарий их использования: каждому регистру соответствует один писатель и много читателей всем модулям кроме SPI регистры нужны индивидуально SPI-модулю регистры нужны как массив Может кто подскажет какие-нибудь образцы хорошего стиля на эту тему )
-
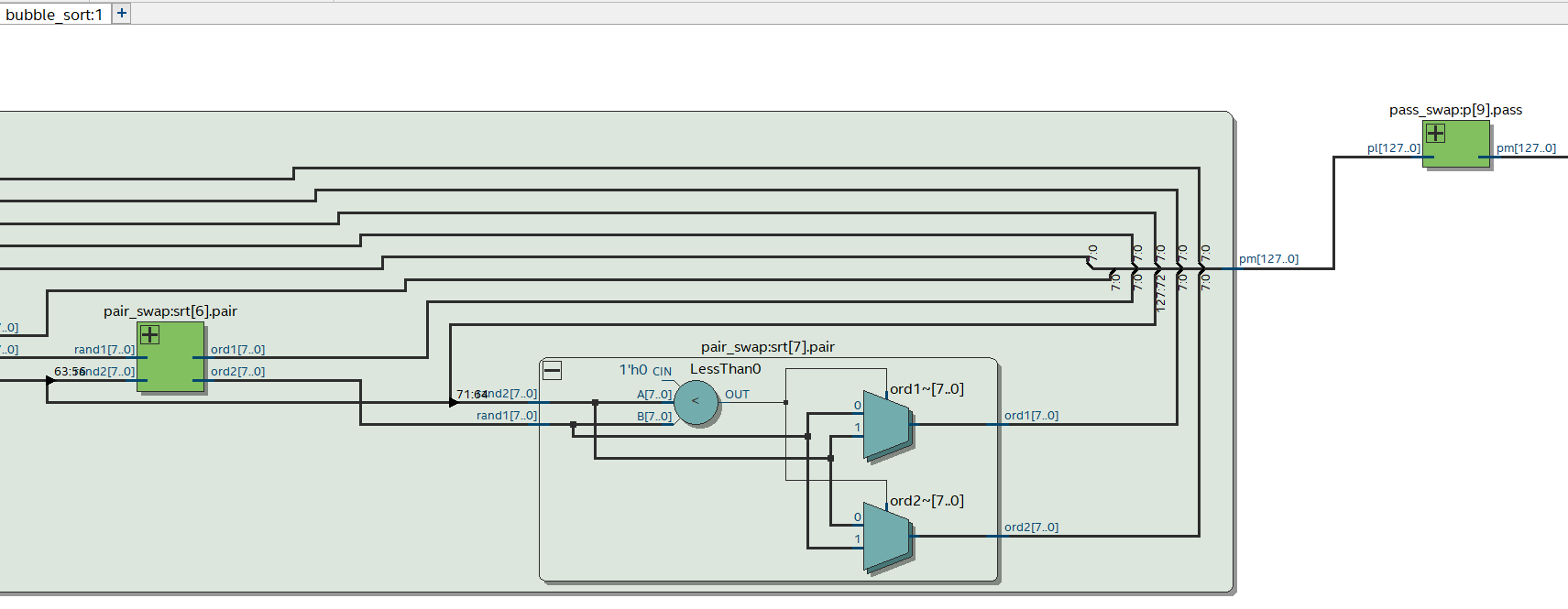
Всем привет! Тут, просто, ради интереса, довелось ответить на такой вопрос: Пузырьковая сортировка в ПЛИС "за один такт". Другими словами, только в виде комбинаторной логики, без синхросигнала и регистров. Verilog (не System). На входе и на выходе - массивы. На выходе - отсортированный. Чтобы было в общем виде, через параметры и циклы generate. Оказалось довольно интересно. Первое что поразило. Это слишком большая ошибка в оценке времени на разработку. Задача казалась очень простой. Сразу было ясно, что это будет многократное повторение простейшего модуля с перестановкой двух элементов. Сначала воспроизвёл алгоритм в perl, чтобы со стороны взглянуть на проблему. На это ушёл вечер - не считаем его вообще. Далее, накидал структуру модулей (перестановка, один проход, собственно сортировка и тестбенчи для всех) и решил что вся разработка с этого момента займёт пару вечеров... В первый вечер стало ясно, что знания по циклу generate не в один момент загружаются в голову... Пришлось поменять тактику: раскидать модули по файлам, прикрутить контроль версий. Долго-ли коротко-ли, ушло раз в 5-6 больше времени. И это довольно характерный коэффициент для меня. Просто до смешного стабильный показатель )) Это один результат, который надо ещё осмыслить )) Ну и оказалось, что этот проект интересно разглядывать через утилиты Квартуса. Особенно в процессе знакомства с generate + цикл. Очень наглядно: 1. RTL Viewer (см. скрин) 2. Timing Analyzer - путь с максимальной задержкой как меняется от размерностей массива 3. Technology Map Viewer (тут можно увидеть как всё конвертируется в таблицы истинности*) * если я правильно понимаю м.б. кому-нибудь пригодится И конечно интересны комментарии и соображения по всем задетым темам, если у кого они есть. bubble_sort.7z
-
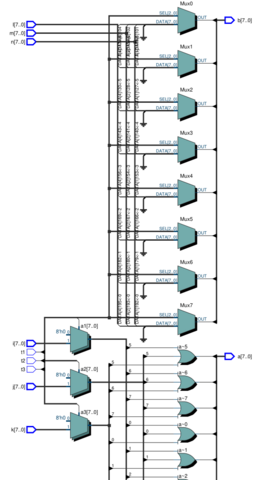
Как правильно описать мультиплексор
Вадим Н. опубликовал тема в Языки проектирования на ПЛИС (FPGA)
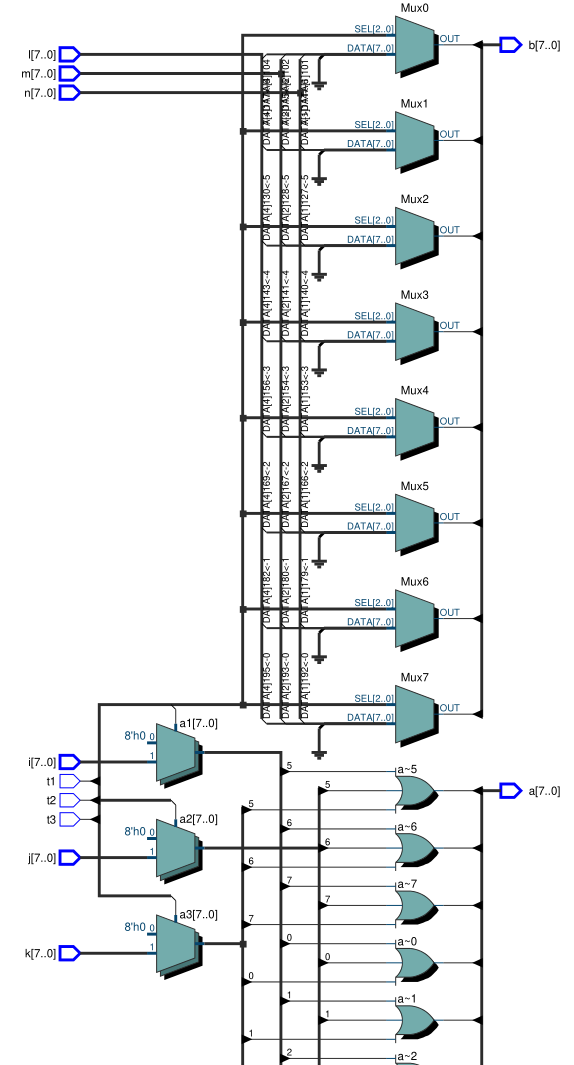
Требуется мультиплексор для задачи которая в общем описана в testbench ниже. Сначала я интуитивно всё это нарисовал и всё казалось нормально (см. первый вариант). Но потом стало ясно что ни кто так не делает. Поискал по форуму всё с "mux" (в частности). Написал вариант генерирующий мультиплексор (см. второй вариант). С использованием for для генерации комбинаторной логики всё ясно, но тут управляющий сигнал по другому устроен. И переделывать его, вроде бы, нет оснований. Так что я case использовал. Может будут какие-нибудь замечания... правильно ли использовать always @ (*) ?