enzaime
-
Постов
83 -
Зарегистрирован
-
Посещение
Информация о enzaime
-
Звание
Частый гость
")
Посетители профиля
1 194 просмотра профиля
-
тактовый сигнал LVCMOS
enzaime ответил enzaime тема в от ТТЛ до LVDS здесь
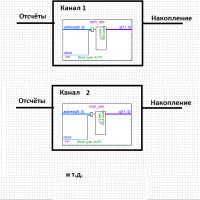
А что тогда имеется ввиду вот здесь? Это функциональная диаграмма платы из руководства пользователя И в том же документе ниже Или имеется ввиду что максимум можно 500 МГц, но его вы нигде не возьмёте? И вообще с этими отладочными платами хрень какая-то, все их делают так что нужно подавать внешний тактовый сигнал, хотя какая сложность использовать микросхему умножения входной частоты с кристалла на плате? И гибкость (мол задал другой коэффициент и получил нужную частоту), и запары для пользователя меньше, подал питание, внешний модуль ещё какой-нить подключил и радуйся. Но это так, я просто ною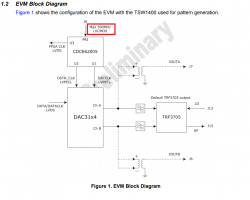

-
тактовый сигнал LVCMOS
enzaime опубликовал тема в от ТТЛ до LVDS здесь
Хочу приобрести отладочную плату DAC3154EVM. Для работы платы требуется тактовый сигнал с характеристиками 1.5 Vrms LVCMOS 500 MHz. Я так понимаю, что это характеристики синусоиды с амплитудой 2.1в, частотой 500 МГц. Этот сигнал идёт на микросхему тактового генератора CDCE62005 Вот участок схемы Этот сигнал идёт с входа EXT_REF_CLK на вывод pri ref+ Вот описание выводов Вот их электрические характеристики Я не могу понять какие характеристики должен иметь входной сигнал, по току и напряжению, также какое смещение и можно ли такой сигнал подать с генератора сигналов с выходом 50 Ом?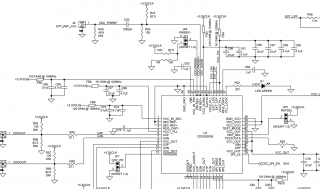


-
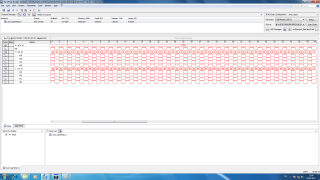
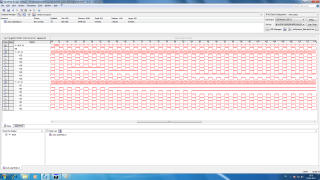
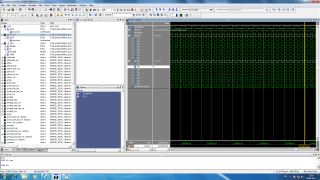
В общем штука такая в процессе изучения ПЛИС заметил вот какую вещь: по мере уменьшения емкости чипа (total logic elements) начинаются всякие странные вещи. Например, там где должна быть 1 там 0 и наоборот. Я сделал тестовый проект, в котором виден этот эффект. Использую плату CoreEP4CE10 c ПЛИС EP4CE10F17C8 и тактовым генератором на 50 МГц Реализуется следующее: n параллельных процессов в которых m раз выполняется * и / проц 1: *,/ проц 2: *,/ *,/ проц 3: *,/ *,/ *,/ *,/ проц 4: *,/ *,/ *,/ *,/ *,/ проц 5: *,/ *,/ *,/ *,/ *,/ *,/ и т.д. каждая ветка описывается так: library IEEE; use IEEE.STD_LOGIC_1164.all; use ieee.std_logic_unsigned.all; use ieee.std_logic_arith.all; use ieee.std_logic_misc.all; entity vetka is generic(n:natural:= 10); port( clk : in STD_LOGIC; a: in std_logic_vector(15 downto 0); r:out std_logic; chisl:out std_logic ); end vetka; --}} End of automatically maintained section architecture arch of vetka is function vetv (a: std_logic_vector) return std_logic_vector is variable c: std_logic_vector(29 downto 0); begin c := x"000"&"00"&a; for i in 1 to n loop c := conv_std_logic_vector(conv_integer©*conv_integer©,30); c := conv_std_logic_vector(conv_integer©/conv_integer(c(7 downto 0)),30); end loop; return c; end; function merg (d: std_logic_vector) return std_logic is variable c: std_logic:='0'; begin for i in 0 to 29 loop c := c or d(i); end loop; return c; end; signal d:std_logic_vector(29 downto 0):=x"0000000"&"00"; signal st:std_logic_vector(3 downto 0):=x"0"; begin r <= or_reduce(d); chisl <= merg(d); process(clk) begin if(rising_edge(clk)) then if(st = x"0") then d <= vetv(a); st <= x"1"; end if; if(st = x"1") then st <= x"0"; d <= conv_std_logic_vector(0,30); end if; end if; end process; -- enter your statements here -- end arch; функция or-reduce(d) регистрирует изменение сигнала d, изменяя своё значение на противоположное при каждом изменении сигнала d. далее генерируются n процессов длины m library IEEE; use IEEE.STD_LOGIC_1164.all; use ieee.std_logic_unsigned.all; use ieee.std_logic_arith.all; entity gabage is generic(m:natural:=5); port( clk : in STD_LOGIC; etalon: out std_logic; a: in std_logic_vector(15 downto 0); vetv : out STD_LOGIC_vector(m downto 0); rez: out std_logic_vector(m downto 0); alls: out std_logic ); end gabage; --}} End of automatically maintained section architecture arch of gabage is signal etst:std_logic_vector(3 downto 0):=x"0"; signal et:std_logic:='0'; signal vrez:std_logic_vector(m downto 0); component vetka is generic(n:natural:= 10); port( clk : in STD_LOGIC; a: in std_logic_vector(15 downto 0); r:out std_logic; chisl:out std_logic ); end component; function merg (d: std_logic_vector) return std_logic is variable c: std_logic:='0'; begin c := d(0); for i in 1 to m loop c := c and d(i); end loop; return c; end; begin vetv <= vrez; etalon <= et; alls <= merg(vrez); G0: for i in 0 to m generate k1:vetka generic map(n => i) port map( clk => clk, a => a, r => vrez(i), chisl => rez(i) ); end generate; process(clk) begin if(rising_edge(clk)) then if(etst = x"0") then et <= '1'; etst <= x"1"; end if; if(etst = x"1") then et <= '0'; etst <= x"0"; end if; end if; end process; -- enter your statements here -- end arch; В общем сначала я думал увидеть задержку выполнения операций для каждого процесса, сравнивая r и etalon увидеть какое-то отставание на каждой ветви от эталона (etalon). Сигнал alls объединение сигналов готовности через функцию логическое И Да и главный файл: Выходная частота pll 200 МГц входная 50 МГц Вот так это дело работает в симуляторе modelsim (gate level), например, для 8 веток Смотрел работу в чипе с помощью логического анализатора, работающего на частоте 200 МГц (частота выходных сигналов 100 МГц) Если генерировать для 4 ветвей, то всё работает как надо ( правда каких-то задержек я не увидел, возможно, неправильно смотрел) отчёт компилятора Вот что отображает логический анализатор Но если сгенерировать для 8 ветвей, то что-то непонятное происходит картинка сильно отличается от того, что в симуляторе. Сигналы готовности n должны быть равномерными с частотой 100 МГЦ, но по факту бывает так что высокий уровень несколько тактов не сменяется низким, хотя в коде нигде такого не прописано отчёт компилятора Я как-то не понимаю почему это происходит. Тоесть понятно что я что-то делаю не так, но вот что именно не понимаю Может кто сталкивался с чем-то подобным? Вот ссылка с проектом на яндекс диске https://yadi.sk/d/FEwjHm0G3EwbyD
-
ДПФ на ПЛИС
enzaime ответил enzaime тема в Работаем с ПЛИС, области применения, выбор
В общем набросал я схемку вот здесь видно что можно сделать несколько блоков rom памяти с таблицей синусов, а дальше чтобы получить нужный коэффициент надо просто выбрать его из таблицы. И для каждого канала хранить такую таблицу (например 100 каналов и 100 одинаковых таблиц, чтобы за 1 такт можно было получать больше 2 значений, а если бы все каналы обращались бы к 1 таблице, то действительно за 1 такт я бы больше 2 значений из памяти не получил бы). Это то что мне первое в голову пришло. Дальше да можно уменьшить количество хранимых значений таблицы (используя свойства функций sin, cos) Но может есть ещё какие варианты? Помимо тех что выше описаны? Мне просто интересно какой вариант самый правильный ( я понимаю, что есть много вариантов, вот какой будет реализован такой и будет правильным)