Амур работает на 32МГц, при этом QSPI - на 16МГц, соотвественно, требуется 64мб/с, а есть 8, но хорошая новость в том, что кэш таки есть, он не в процессоре, а не блоке QSPI, его объем составляет 1кБ.
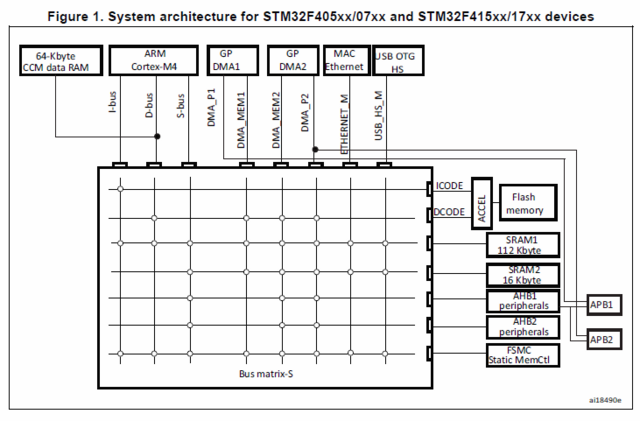
Кстати, на STM32 флэш весьма медленная, около 30МГц, соответственно какой-нибудь STM32F4 на 180МГц будет иметь 6 циклов ожидания, а ведь у него ART акселератор - тот же кэш - составляет тот же 1кБ. Но считается, что флэш на нем не сильно его тормозит. А ведь это почти как в Амуре по количеству циклов ожидания. Хотя на QSPI еще и команды, протокол передачи... тут нужно просто замерять на самом деле.
На счет TCM памяти - это память, которая не имеет задержек доступа из за загрузки матрицы шин, для сигнальных вычислений или чего то максимально реалтаймового. Но минус - не доступна для DMA.