Поиск
Показаны результаты для тегов 'create_generated_clock'.
-
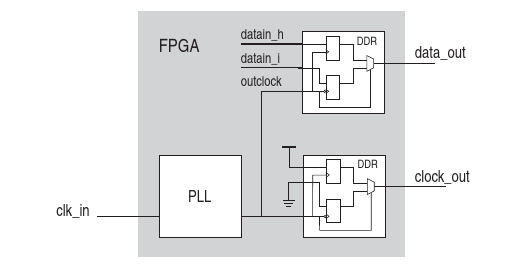
Доброго всем времени суток! Пытаюсь понять, как у Gowin описать констрейнты для синхроного интерфейса, у которого выходные регистры для сигналов интерфейса тактируются от PLL, а тактовый сигнал для передаваемых данных генерируется с помощью ODDR. Суть задачи вполне типовая и хорошо описана, например, в документации на Альтеру: Констрейнты для тактового сигнала Альтера предлагает описывать так: create_clock -name input_clock -period 10.000 [get_ports clk_in] create_generated_clock -name common_clock -source \ [get_pins PLL|inclk[0]] [get_pins PLL|clk[0]] create_generated_clock -name output_clock -source \ [get_pins DDR|ddio_outa[0]|muxsel] [get_ports clk_out] Для Gowin это выглядит приблизительно так: create_clock -name sys_clk_i -period 20 -waveform {0 10} [get_ports {sys_clk_i}] create_generated_clock -name clk -source [get_ports {sys_clk_i}] -multiply_by 12 -divide_by 5 [get_pins {main_pll_inst/rpll_inst/CLKOUT}] create_generated_clock -name clk_o -source [get_pins {clk_oddr_inst/Q0}] -multiply_by 1 [get_pins {clk_o_obuf/O}] В результате Gowin ругается совершенно странным образом: ERROR (TA2004) : "constraints/timing.sdc":3 | Cannot get clock with name '' WARN (TA1052) : Generated clock is ignored Т.е. он должен был бы найти тактовый сигнал clk, но не находит ничего. Кто-нибудь имел опыт решения подобной задачи на Gowin?