


johan
-
Постов
78 -
Зарегистрирован
-
Посещение
Сообщения, опубликованные johan
-
-
Всем привет!
Мы ищем коллегу - хорошего FPGA разработчика для создания сетевых решений на базе 10G / 40G Ethernet с использованием современных чипов фирмы Intel (Altera) (Arria 10 и Stratix V).
Мы - финансово-технологическая компания, специализирующаяся на алгоритмической торговле на глобальных финансовых рынках.
Обязанности:
- Разработка IP-ядер для обработки сетевого трафика (IP, TCP, UDP и др.)
- Разработка IP-ядер для математических вычислений и хранения/обработки данных
- Верификация IP-ядер, отладка на реальном оборудовании
Требования к кандидатам:
- Опыт разработки - не менее 2 лет
- Знание языков Verilog / SystemVerilog
- Понимание принципов оптимизации по времени, ресурсам, пропускной способности
- Опыт разработки высокоскоростных схем (от 100 MHz)
Будут преимуществом:
- Опыт работы с интерфейсами 10G / 40G Ethernet, PCI Express
- Опыт работы с FPGA фирмы Intel (Altera) серий Stratix и Arria
- Опыт работы с Quartus II, Qsys, TimeQuest, ModelSim
- Теоретические и практические знания по сетевым протоколам (Ethernet, IP, TCP, UDP) и PCI Express
- Опыт реализации структур хранения данных (деревья, хэш-таблицы, списки и тд.)
- Опыт работы с внешней памятью (DDR3, DDR4)
- Навыки программирования на C/C++
- Знание скриптовых/интерпретируемых языков для оптимизации процесса разработки
- Знание Linux на уровне уверенного пользователя
Что мы предлагаем:
- Помощь в релокации кандидату и членам семьи в Берлин
- Гибкий график работы
- Регулярные выездные рабочие сессии в разных точках Европы
- Молодой коллектив выпускников ведущих вузов
- Оплачиваемые компанией занятия иностранным языком
Мы хотим узнать Вас лучше, поэтому просим ответить на следующие вопросы:
- С какими внешними протоколами (PCIe, Ethernet, SPI, UART, I2C и т.д.) вам приходилось иметь дело на FPGA и на каком уровне? Описывали его самостоятельно, исправляли уже имеющийся или просто брали готовый модуль и использовали.
- С какими динамическими структурами вы сталкивались? Какие практические и теоретические знания вы имеете в данном вопросе. Какие из них реализовывали самостоятельно на Verilog или C++.
- Есть ли у вас знания сетевых и транспортных протоколов (IP, TCP, UDP)? Насколько эти знания глубокие?
- Опишите пожалуйста самый интересный или самый большой проект, в котором вам приходилось принимать участие. Укажите свою роль, сколько было исполнителей, насколько большой получилась система, на какой частоте работала, и сколько заняло времени вся разработка. Чем подробнее тем лучше.
- Можете ли вы прислать пример своего кода (Verilog/SystemVerilog)? Если есть код на github/bitbucket, то достаточно ссылки на репозиторий.
Ждем Ваше резюме, ответы на вопросы, как и встречные вопросы/предложения на: [email protected] (Можно на русском языке).
Примечание:
- Немецкий язык для работы в нашем отделе не нужен. Достаточно русского и технического английского.
- Есть возможность релокации не в Берлин, а на Кипр.
- Все уточнения по условиям работы, вилке зп, количеству плюшек в день и пр. желательно спрашивать по указанному адресу - я просто помог разместить объявление на этом форуме. Конечно, можно спрашивать вопросы в этом топике, у меня в личке тут/на хабре/линкедине, но не уверен, что я на всё смогу ответить: в некоторых я некомпетентен, а некоторую информацию не готов разглашать. Надеюсь на Ваше понимание в этом вопросе.
-
А что в отчёте сообщает - какие нетлисты для ваших партишинов были применены? Включена ли смарт-компиляция?
novartis, посмотрите всё-таки отчет о сборке.
Вам нужен файл PROJECT_NAME.merge.rpt, там есть табличка:
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ ; Partition Merge Netlist Types Used ; +--------------------------------+----------------+-------------------+------------------------+---------------------------------------------------------------------------------------------------+ ; Partition Name ; Partition Type; Netlist Type Used; Netlist Type Requested; Partition Contents ; +--------------------------------+----------------+-------------------+------------------------+---------------------------------------------------------------------------------------------------+
Где и будет написано, что он использовал.
Если там будет Source, вместо Post-Fit, то надо смотреть лог компиляции, он там говорит, почему выбрал Source, вместо Post-Fit.
Один из кейсов, если не ошибаюсь, у разных патрициях, которые общаются между собой выставлена разная оптимизация на "границах", и из-за этого происходит лишний пересинтез.
-
Коллега, а можете рассказать в двух словах, что это за чип (семейство), сколько там было ячеек занято, какие хоть частоты?
-

В общем, насколько я понял, профессиональные "железячники" использовать булевые операции вида if(vector) и if(!vector) не приемлют.Есть еще следующий уровень "профессиональных железячников" (которые и под ASIC пишут).
Они не используют always @( * ) / always_comb и if в языке Verilog/SystemVerilog.
И это не шутка.
Объясняют тоже стабильностью и одинаковостью моделирования и реализации в железе и т.п..
assign и тернарный оператор (? :) наше всё.
-
Кстати, а кто конкуренты, покажите пальцем (можно на hh)?
Ну, зависит от сферы.
Если брать направление измерительного ободрудования. то некоторые похожие девайсы делает Кометех.
Если телекоммуникационное с примесью фильтрации/шифрования, то это НорсиТранс, НТЦ Протей, Элтех (правда, там вроде нет FPGA) + компании, которые напрямую или косвенно связаны с ФСБ, и о которых не так много информации в интернете.
Если брать направление девкитов/плат для разработки, то это ЗАО "ИнСис", ЗАО "Алмаз-СП", Инмис (inmys.com).
Если брать измерительное оборудование во всем мире,то сюда добавляются EXFO, Accedian, JDSU, Fluke.
-
Опубликовано · Изменено пользователем johan · Пожаловаться
На правах человека, который точно знает, почему конкретна эта вакансия возникла, позволю себе немного оффтопа:
1. У ребят (НТЦ Метротек) много есть идей и задач, как продакшен, так и исследовательских. Если решать все задачи будет один человек, то конкуренты, у которых пять людей решат эти задачи быстрее (Капитан Очевидность).
2. Если зайти на сайт в раздел вакансии (http://metrotek.spb.ru/hiring.html), то там расположена фраза "Для толковых инженеров у нас всегда открыты вакансии". Она там висит уже лет пять (а то и больше).
Можно предположить, что это всё из-за текучки людей, которая может происходить по всем понятным причинам. Если Вам это важно и интересно, то лучше всего спрашивать у ТС в личке или на собеседовании, возможно он ответит на этот вопрос.
Как я понял des333 хочет, что бы разработчики просто присылали своё резюме, где написана ожидаемая заработная плата.
Если ваша ожидаемая ЗП в Питере 10К$ на этой или похожей вакансии, то просто напишите об этом в резюме и присылайте. Вот и всё.
На сколько мне известно, НТЦ Метротек - компания негосударственная, поэтому если из Вашего резюме будет ясно, как используя ваши знания контора сможет получать в месяц доход больший, чем ваша зарплата, то возможно и 10К$ будут Вам платить (ну, потому что это тупо выгодно). (Есть нюанс, конечно, что если остальные разработчики вдруг получают намного меньше, то возможно возникнет напряженность, но это уже дело менеджмента как разрулить эту проблему.)
Если Вам не нравится манера подачи объявления без вилки зарплат, то зачем агрессировать?
(Мне, например, это тоже не нравится: мне комфортнее в вакансии сразу видеть порядок цифр.)
Мы все вроде люди взрослые, и если компания решила, что без вилки зарплат она лучше найдет сотрудника, чем с ней, значит ей виднее. Правы они или нет - покажет только время. Если не найдут, и конкуренты обойдут, ну, значит, были не правы :)
Понятно, что из США можно писать всё что угодно и про 10K$ и про остальное, как бы подтрунивая над теми, кто живет в России, но вроде говорят, что совет надо давать тогда, когда его просят.
Если des333 спросит на форуме:
Блин, ребята, уже полгода не могу найти топового FPGA-разработчика, дайте совет как найти.то тогда можете писать все свои советы. Тогда они будут уместны.
-
Опубликовано · Изменено пользователем johan · Пожаловаться
Спасибо за ответ, видимо предстоит много работы.Ну, некоторую работу можно сократить.
Можно, например, начать с того, чтобы не делать полноценный VGA, а сделать чернобелый терминальный режим 80x25 (или 80x30).
Это позволит вам выводить текст с использованием 80 * 25 * 8 (бит на символ) = 16000 бит, что легко умещается в блоки памяти в самой FPGA.
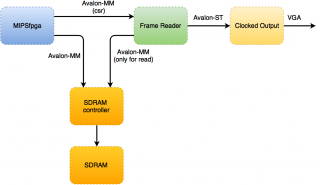
Тогда получается вот такая схема:

Т.е:
1. VGA контроллер отдает vsync/hsync и номер пикселя (x/y в 640x480), который сейчас надо выводить.
2. По номеру пикселя понимаем какой ряд и строчку надо выводить (char_x/char_y в 80x30), и сдвиг в этом символе.
3. Отправляем их на charbuffer, который нам выдает то, какой именно символ надо выводить.
4. Отправляем номер символа на font RAM, которая хранит все возможные символы (типа, алфавит).
5. По сдвигу в символе (см. п.2) и той информации, что хранится в font RAM понимаем, нам надо выводить пустоту или закрашивать пиксель (если у нас чернобелый режим).
6. Выводит это на экран. Параллельно с этим всем конвеером сигналы vsync/hsync задерживаются на нужное количество тактов, для того что бы это всё было выровнено. Хотя скорее всего правильнее тащить эти сигналы (vsync/hsync) через конвеер, для того, чтобы точно не было расхождения, если вы добавите где-то задержку в конвеере, но не учтете это в другом месте.
Подобную схему я делал когда делал тетрис (исходный код) для вывода строчек "Score, Lines, Level, New Game".
Процессор занимается только тем, что пишет в charbuffer те символы, которые он хочет чтобы были на экране через Avalon-MM или AXI.
Тем самым вы сможете писать "hello world from MIPSfpga" на экране :)
P.S. Скорее всего в интернете где-то есть готовые С-библиотеки, которые производят всю нудную работу по переносу строк, сдвигам для такого терминала и пр.
-
Т.ч. технически оно в каком-то виде есть и даже работает. Но вот есть вот такие неприятные вылеты (лечатся ударами в бубен, заключающимися в подборе имён в модпортах). Ситуации этой уже несколько лет, никто ничего там не делает на эту тему. Насколько могу судить, все усилия там сосредоточены на продвижении толстых ПЛИС, QSys и подобном.
Кстати, Альтера использует SV-интерфейсы в своем коде (например, в автосгенерированных исходниках после OpenCL), но без модпортов.
-
Опубликовано · Изменено пользователем johan · Пожаловаться
Как выполнить буферизацию в таком проекте? Я вижу только один способ ядро накидывает в модуль vga нужные для отображения данные когда массив для его хранения заполняется vga модуль начинает считывание их и отображение?Перечитал Ваше первое сообщение более внимательно, и понял, что вопрос с двойной буферизацией был лишним - я его задал на автомате.
Про тайминги вы всё-таки ответьте, потому что лучше было бы, если бы они укладывались ;)
Мне кажется это из за того что есть очень большая временная разница между координатами которые нужно записать и получением цвета который мы и запишем в блок.Ммм, а почему бы не узнать какая задержка между координатами и получением цвета?
Например, просимулировать в ModelSim'e? MIPSfpga можно симулировать или там зашифрованный код?
Если нельзя, то почему бы не глянуть эту задержку в SignalTap'e?
Увидев эту задержку Вы сможете сделать вывод, может ли она приводить к такой картинке или нет.
Как реализовать этот блок что бы избежать этого?Как я понял, у вас плата DE0-CV, и судя по даташиту у нее четырехбитных VGA.
640 * 480 * ( 3 (RGB) * 4 (bits) ) = 3686400, что многовато, а, следовательно, если мы хотим такое изображение выводить, то нам нужно использовать внешнюю память.
На этой плате стоит внешняя 64MB SDRAM, чего должно нам хватить с лихвой.
Я бы сделал так:
1. Использую какую-то готовую корку от Альтеры (уверен, что в примерах к этой плате она идет, названия сейчас не скажу), которая позволяет писать/читать через интерфейс Avalon-MM в эту память.
2. Подключаю эту память к MIPSfpga, делаю какие-то функции/макросы которые позволяют писать/читать в эту память (т.е. просто чтение по какому-то оффсету).
3. Беру готовые альтеровские IP-ядра Frame Reader и Clocked Output из Altera VIP. Подключаю в систему.
4. Смотрю драйвер для Altera Frame Reader, портирую оттуда функции altvipfb_start_hw и altvipfb_disable_hw.
5. Настраиваю через Avalon-MM (csr) Altera Frame Reader, чтобы он начал читать например с нулевого адреса внешней памяти.
6. Через Avalon-MM с помощью функций, разработанных в п.2 пишу нужные мне цвета в нужных пикселях (адресах). Они отобразятся на экране.
В таком подходе вы используете готовые компоненты, однако по ресурсам (FPGA) это будет дорогое удовольствие :)
Двойной буферизации в таком варианте нет, и если у вас будет картинка быстро динамически менятся, то эти эффекты возможно будут видны. Я примерно всё это проделывал, когда поднимал VGA на плате с Cyclone V SoC в linux'e (т.е. делал линуксовый фреймбуфер), и там этих эффектов не заметил, хотя выводил и GUI (window manager).
UPD:
Схему приложил в аттаче.
Стрелки идут от мастера к слейву.
-
Опубликовано · Изменено пользователем johan · Пожаловаться
Но мне этого не достаточно, так как идей много, а хороших инженеров мало.Поэтому вы решили стать еще одним инженером?
СЗОТ,
но почему нельзя просто нанять гуру (который вы хотите, чтобы Вас обучал) к себе и у него консультироваться по техническим вопросам?
Недоверие, что человек может в любой момент уйти + кража идей? Дак это решается хорошим и правильно составленным контрактом.
-
Уложился ли проект по таймингам?
Делаете-ли какую-то двойную буферизацию?
-
Ну, мы же не знаем какая плата у ТС, какие требования по ресурсам/частоте/времени на разработку :)
Если под руками Stratix/Arria и задача большие массивы обрабатывать, то OpenCL/HLS - почему бы и нет?
-
Опубликовано · Изменено пользователем johan · Пожаловаться
Всем привет.
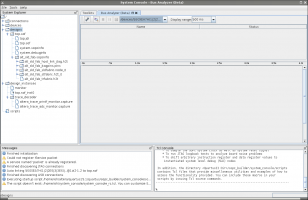
В проекте для анализа некоторых Avalon-MM шин решил применить Bus Analyzer Toolkit.
Отметил те интерфейсы (штук пять, причем в нескольких клоковых доменах), которые хочу смотреть в Qsys (как по инструкции), пересобрал, перешил FPGA.
Подключился через JTAG и зашел в System Console. System Console распознала прошивку, но в анализаторе шины никаких сигналов не видно (там где Name и Status).
(см. скриншот в аттаче).
Нажатие "старт" к особому успеху не приводит - ничего не меняется (каких-нибудь графиков и пр.)
Судя по отчёту фиттера модули для накопления статистики по интерфейсу создались.
Я понимаю, что эта фича вроде бы бета и может не сильно стабильно работать на больших проектах, но хотелось бы на нее посмотреть :)
Было ли у кого-то похожее? Может это какая-то известная проблема и есть простой workaround?
Версия: Quartus Prime Version 15.1.1 Build 189 (без патчей)
Заранее спасибо! :)
-
Опубликовано · Изменено пользователем johan · Пожаловаться
В ресурсах на офсайте de1-soc есть архив с Linux Ubuntu Desktop.
Для поднятия фрейбуфера вам надо:
- правильно соединить в QSYS модули Frame Reader и Clocked Output из Altera VIP
- прописать в DTB (назначив правильный адрес в системе)
hps_0_h2f: bridge@0xc0000000 { compatible = "altr,bridge-1.0", "simple-bus"; reg = < 0xc0000000 0x20000000 >; #address-cells = < 1 >; #size-cells = < 1 >; ranges = <0x00000000 0xc0000000 0x00000080 >; alt_vip_vfr_1: vip2@0x0 { compatible = "ALTR,vip-frame-reader-13.0", "ALTR,vip-frame-reader-9.1"; reg = < 0x00000000 0x00000080 >; max-width = < 800 >; /* MAX_IMAGE_WIDTH type NUMBER */ max-height = < 600 >; /* MAX_IMAGE_HEIGHT type NUMBER */ mem-word-width = < 128 >; bits-per-color = < 8 >; }; };- правильно всё подключить к пинам VGA
- использовать драйвер https://github.com/altera-opensource/linux-...bdev/altvipfb.c
- после прошивки FPGA, загрузки с правильным DTB и загрузки драйвера вы увидите что-то типа:
[ 66.424283] altvipfb c0000000.vip2: fb0: altvipfb frame buffer device at 0x2c000000+0x12c000
И появится /dev/fb0.
-
- Корпоративный VHDL Coding Style Guidelines
- Корпоративный Verilog Coding Style Guidelines
СЗОТ:
Есть возможность выложить ваш корпоративный Coding Style на VHDL и Verilog?
-
Вы бы написали к какой борде какие SFP модули хотите подключить... (кстати, не забывайте, есть SFP (<=1G), а есть SFP+ (10G)).
Будете гонять Ethernet?
Про подключение 10G Ethernet к FPGA можно глянуть тут: https://habrahabr.ru/company/metrotek/blog/234369/
-
iiv,
напишите, пожалуйста,
Как-будет происходить отладка для тех, кто будет удалённо это делать?
TeamViewer, ssh?
Будет ли доступен SignalTap?
Можно ли отлаживаться в ночное время, на выходных (для вариантов тех, кто не хочет уходить с работы и делать ночью/на выходных :) )?
-
Опубликовано · Изменено пользователем johan · Пожаловаться
Хорошее описание вакансии.
Респект!
Не соглашусь, что задача 5 самая "дорогая" в этом списке, но ТС, разумеется, виднее.
Так же интересно, что подразумевается (какие числа) под аппаратным пиком в каждой из задач, либо это информация скрыта, и кандидатам самим надо определить? :)
P.S.
Можно ли узнать, где (название компании/сайт) предлагает работать ТС?
-
Опубликовано · Изменено пользователем johan · Пожаловаться
На рокетбордс появился набор "курсов" для Altera SoC:
от обзора что-это-такое до написания драйверов:
http://rocketboards.org/foswiki/view/Docum...CWorkshopSeries
Я одним глазом посмотрел - в третьей "лабораторной" есть куча примеров простых драйверов (в том числе и с прерываниями).
-
А есть разница в скорости при использовании UDP или TCP?
Ну, смотрите:
TCP гарантирует доставку и ждет ответов от получателя, следовательно пока не отреагировала та сторона некоторое время мы будем простаивать и ждать ответа. Так же необходимо следить за состоянием сессии и т.д.
TCP заголовок 16 байт (если без опций смотреть), а UDP заголовок - 8. Следовательно при одной и той же длине пакета с UDP можно передать на 8 байт больше с каждым пакетом.
Для TCP обязательно рассчитывать контрольную сумму (а она считается в том числе и по данным), для UDP контрольную сумму можно не рассчитывать и заполнить нулями (т.е. снизить нагрузку на процессор дополнительными расчетами, однако все эти расчеты может делать сетевая карточка/встроенное MAC-ядро в HPS, если это поддерживается и настраивается).
Так, в случае UDP можно заранее подготовить весь заголовок (если известно куда отправляются данные и получатель не меняется), и только подставлять данные (просто склеивая) и отправлять целый пакет (с Ethernet/IP/UDP заголовками) через RAW сокет.
Разница между TCP и UDP есть. Не думаю, что на HPS UDP НАМНОГО будет быстрее, чем TCP, он немного проще, вот и всё.
Если использовать Jumbo фреймы, то можно немного снизить нагрузку (будет меньше прерываний и пакетов в принципе).
В доке Cyclone V Hard Processor System Technical Reference Manual в разделе про EMAC написано:
Programmable frame length supporting standard and jumbo Ethernet frames (with size up to 3800 bytes)Насколько это работает в этом MAC-ядре я не знаю - не пробовал.
Если данные, которые вы передаетё хорошо сжимаются, то можно попробовать сжимать, а потом передавать :)
-
Вы используете TCP или UDP?
Вы хотите использовать большие (jumbo) фреймы для передачи (packet_size = 8192)?
-
Опубликовано · Изменено пользователем johan · Пожаловаться
Так получилось, что коллеги топикстартера вышли на меня и попросили глянуть этот кейс на тех платах, на которых я работаю.
Я посмотрел - действительно, воспроизводится - результат аналогичный (видны пропуски).
Для исключения ошибки в FPGA коде я написал свой, который делает аналогичные действия, но пишет шириной данных по 32 бита (вместо 128, как было у автора). Результат тоже аналогичный - видны пропуски, хотя я писал и через интерфейсы fpga2hps и через fpga2sdram.
Если открыть Cyclone V Hard Processor System Technical Reference Manual Figure 1-2: HPS Block Diagram, то видно, что при использовании этих интерфейсов поток данных идет в обход процессора ARM (MPU Subsystem), в том числе его кэша L2 (64 КБ). Следовательно, когда программа в юзерспейсе просит процессор прочитать данные из DDR-памяти, то если данные остались в кэше, то он вычитает из кэша.
Эта идея подтвердилась тем, что в той же самой утилите перед запуском DMA-транзакции сделали фейковую обработку данных вида:
#define BIG_ARR_SIZE 1000000 uint32_t* big_arr; big_arr = malloc( BIG_ARR_SIZE * sizeof( uint32_t ) ); if( big_arr == NULL ) { printf("big_arr: can't alloc\n"); exit( -1 ); } int i; uint32_t sum = 0; for( i = 0; i < BIG_ARR_SIZE; i++ ) { big_arr[i] = rand(); } for( i = 0; i < BIG_ARR_SIZE; i++ ) { sum += big_arr[i]; }А после DMA-транзакции делали печать sum (для того, чтобы ничего не соптимизировалось).
Идея этой фейковой обработки в том, что данные из кэша которые принадлежали той области памяти, куда будет писать FPGA, сбросятся в DDR.
А когда процессор попросит даные из этой памяти, то он будет обязан взять их из DDR-памяти - т.е. самые новые.
На железе было попробовано - действительно пропуски пропали.
Хак с фейковыми расчетами никуда не годится в реальных задачах: при выделении памяти под DMA вы должны гарантировать, что когда процессор
будет их забирать, он возьмет самые актуальные.
Самый правильный и классический путь - это писать драйвер, который будет заниматься выделением такой памяти (а так же обрабатывать прерывания, если необходимо).
Например, в драйвере aclsoc (Altera OpenCL) для этого делают так:
kalloc_memory = dma_alloc_coherent(NULL, allocated_size, &dma_handle, GFP_KERNEL); if (kalloc_memory == NULL) { return -ENOMEM; } // kmalloc returns "kernel logical addresses". // __pa() maps "kernel logical addresses" to "physical addresses". // remap_pfn_range maps "physical addresses" to "user virtual addresses". // kernel logical addresses are usually just physical addresses with an offset. // Make the pages uncache-able. Otherwise, will run into consistency issues. vma->vm_page_prot = pgprot_noncached(vma->vm_page_prot); if (remap_pfn_range(vma, vma->vm_start, dma_handle >> PAGE_SHIFT, size, vma->vm_page_prot) < 0) { return -EAGAIN; }В конце статьи про DMA (http://habrahabr.ru/company/metrotek/blog/248145/) Денис (des333) привел пример драйвера, который делает подобное. Можно воспользоваться им, либо написать какой-то свой.
-
Посмотрите в сигналтапе как происходят транзакции.
Возможно это наведет вас на мысли (например, burstcount там равен одному).
-
Опубликовано · Изменено пользователем johan · Пожаловаться
Не смотрите в сторону использования DMA для переброски значений с FPGA в SDRAM?
Чему равен sizeof(data_in_RAM)?


Stratix V vs Arria 10: разный тайминг при чтении из M20K
в Работаем с ПЛИС, области применения, выбор
Опубликовано · Пожаловаться
Всем привет!
При переезде проекта с Stratix V на Arria 10 столкнулся с интересной и неприятной вещью в тех местах, где происходит чтение данных из блоков памяти M20K (и на выходе этой памяти не стоит регистр):
тайминг стал хуже и эти пути мешают укладыванию по частоте. Хотя я ожидал обратных результатов: Arria 10 позиционируется как более продвинутый чип, чем Stratix V.
Для демонстрации этой проблемы я сделал минипроект: https://github.com/johan92/s5_a10_ram_test
В его основе лежит SIMPLE DUAL PORT RAM, где с одного порта происходит чтение данных, прибавление каких-то чисел, и записывание данных обратно в память (через другой порт). В обоих проектах стоит clk с периодом в 3 нс.
Собрать проект можно через make в папках s5/a10. В конце cборки сформируется отчет вида s5/a10.clk.paths.rpt, где будут указаны пути, у которых худший тайминг в проекте.
Эти отчеты при сборке можно найти тут (осторожно, много трафика): https://github.com/johan92/s5_a10_ram_test/.../master/reports
Что мы видим (кроме того, что Arria проиграла в тайминге):
начало худшего пути у Arria выглядит так:
А у Stratix так:
Две наносекунды (1.991) на чтении из памяти на мой взгляд это очень странно (по сравнению с тем, что у Stratix).
Каких-то изменений в структуре блоков памяти я не нашел между Statrix V и Arria 10 в даташитах (которые бы объяснили, что здесь происходит), поэтому я и решил создать этот топик.
Встречали ли вы что-то похожее в своих проектах под Arria 10? Может быть я что-то делаю не так?
Заранее спасибо за идеи и предложения :)
Quartus:
P.S.
Ставить триггер на выходе памяти - это хорошая идея, но меня здесь интересует физика вопроса и маркетинг, который говорит, что Ария во всём лучше Стратикса :)