


pokk
Участник-
Постов
214 -
Зарегистрирован
-
Посещение
Весь контент pokk
-
Взаимодействие двух модулей, task или include ?
pokk ответил pokk тема в Программирование
Stm32+FreeRTOS Можно подробнее про это. -
Взаимодействие двух модулей, task или include ?
pokk опубликовал тема в Программирование
Подскажите как правильнее сделать взаимодействие двух модулей. Первый модуль (ShareParam) считывает значения с АПЦ, суммирует их и пересчитывает в реальные значения параметра в общем на выходе получаем глобальную структуру к которой имеет доступ любой модуль (экран, web … ). Второй модуль эта защита , он должен брать реальные значения(пересчитанные значения) из первого модуля, сравнивать с пороговыми значениями параметра и делать действия (выключать, блокировать...) Вижу два взаимодействие между ними: Первый вариант это из модуля ShareParam выходит сигнал готовности данных, а во втором модуле находиться задача которая ожидает этот сигнал и по нему включает проверку параметра. В принципе мне такое взаимодействие нравиться тем, что модуль ShareParam, развязан и может работать независимо есть ли второй модуль или нет. Но в данном варианте не нравиться: 1) То что используется лишняя задача в модуле защите, так как можно обойти без неё. 2) То что будет достаточно частое, отправлять сигнала готовности т.е частое переключение контента. Второй вариант это в модуле защиты написать функцию, и её вызывать в модуле ShareParam, это исключает все недостатки первого варианта, но логически модули становятся смешанными друг с другом и модуль ShareParam не сможет работать, без модуля защиты. У меня частично старые проекты написаны по второму варианту, и очень раздражает когда ты подключаешь всего один модуль (переносишь в новый проект), а он тянет за собой другой а тот, что-то ещё и ещё и так пока весь проект не перекопируешь. По этому хотелось бы сделать по первому варианту, можно ли как нибудь обойти его недостатки ? -
Ну вот же на первом шаге, конфликт возникает если клиента другой клиент перебьет, в момент модификации confing. Под клиентом я понимаю задачу клиент freertos. Да из задач, одна задача вызывается, когда пользователь физически кнопку ок нажал в меню, а вторая задача вызывается, когда прилетел WEB запрос. Но это так частный случай, пока интересуюсь как в общем это разрулить.
-
И как это происходит в предложенно вами третьем варианте ?
-
Ну вы же сами все правильно написали Именно из за этого и хочу их разделить.
-
Для атомарного доступа к переменной confing В том то и дело клиентов несколько может быть и они все могут модифицировать confing
-
Вообще то нет, это я описал функцию модификацию параметра на клиенте. Если флаг был сброшен, то модифицируем параметр, иначе ждем когда флаг сброситься.
-
А можно по подробнее как это используеться? Если использовать в лоб то это как то так char volatile flag; void ModConfing(void){ //------------------------------------ while(1){ // ожидаем флаг if(flag==1){ break; }else{ taskYIELD(); } } //------------------------------------ //изменение конфигурации //------------------------------------ flag=0; } не вижу чем отличаеться от mutex, он даже проше. А в чем преимущество такого разделение ? Что задачи клиенты не будут подтупливать на момент записи ? Это да запись идет всем блоком, я про такой момент ModAndSaveConfing(VAR1,100); ModAndSaveConfing(VAR2,100); ModAndSaveConfing(VAR3,100); на такой случий надо отдельные функции модификации городить confing.var1=100; confing.var2=200; confing.var3=300; SaveConfing();
-
Флаг занятости, это же mutex? А зачем выделять функцию записи в отдельную задачу?
-
В том то и дело, что эти процессы не сильно то и повторяющиеся, их вызывает пользователь когда нажимает кнопки в меню и в web странице. По этому и решил сразу же в этих обработчиках сделать запись конфигурации в память(внешнуюю), а если все таки наложаться, то по семафором должно все разрулиться.
-
Что бы корректно произошла модификация параметра, ведь его может модифицировать другая задача. Хотя да, для одного и того же параметра наврятли, но структура модифицировать из другой задачи точно может.
-
Удобная модификация параметров структуры confing c зашитой
pokk опубликовал тема в Программирование
Задача такая, есть несколько обработчиков вызываемые через FREERTOS из разных задач. В них должна происходить модификация параметра и запись всей структуру конфигурации в память. Из за того что обработчики вызываются из разных задач, что бы не было переключение контента при модификации параметра его надо заблокировать через mutext. Первое что приходит на ум в лоб xSemaphoreTake(xConfing,portMAX_DELAY); confing.var1=100; confingClcCrc(); SaveConfing(); xSemaphoreGive(xConfing); Но такой вариант не нравиться (загромождает логику). Потом подумал завернуть это все в функцию типа такого: SaveConfing(&confing.var1,100); В принципе, уже более понятно, но тут другая проблема вылезла, функций надо большое количество под каждый тип под массив, под одинарную переменную, а если надо записать больше 1 параметра в одном вызове ? Не гонять же всю структуру в память после каждого байт. В общем подскажите, как это делается что бы было удобно? Или набор функций каких используете ? Была мысль, что бы, передавать сохраняемые данные в одну задачу через очереди, а там производить, модификацию конфигурации + запись. Но отказался от такого нагромождения из за того что, очень малая вероятность, что два обработчика вызовутся одновременно. -
Хранение данных на NOR flash (Кольцевой буфер)
pokk ответил pokk тема в Программирование
Все понял, да походу к данным проще добавить CRC, чем внутри записи его реализовывать А что тут находиться ? Как то тут много типов на увеличенный размер шифрованных данных. Нет нет, я про блок данных (конфигурации/журнала), допустим что было записано 5 аварий(разными блоками COBS) и теперь их надо прочитать, т.е с начала надо прочитать последнюю, аварию(блок COBS), и потом продолжить считать в глубь. И где производить сброс, что при следующий итерации считывание всех 5 аварий, надо считывать с начала, записи а не продолжать, считывать из глубины. -
Хранение данных на NOR flash (Кольцевой буфер)
pokk ответил pokk тема в Программирование
А как добавить CRC в кадр с минимальным, копирование данных ? (без промежуточного буфера) Да походу только так, а я губу раскатал, что так как работаем с потоком байт, то и высчитывать CRC по байтно , в момент кодирование. PS: А функцию считывание с какими параметрами запускаете ? Интересует момент, как сделан выбор продолжить считывания 2-3 блока или надо сбросить и начать с 1 блока. -
Хранение данных на NOR flash (Кольцевой буфер)
pokk ответил pokk тема в Программирование
jcxz, Можете подсказать как у вас идет кодирование CRC ? Сделал кодирование данных в COBS и запись, считывание и декодирование. Кодирование COBS, сделал следующим образом, так как все данные известны, то при начальном вхождении пробегаюсь по массиву данных и нахожу позицию 0, и его выдаю из функции кодирования. Когда начил добавлять CRC возникла проблема что его нету в данных по которым идет кодирование, соответственно COBS отрабатывает не совсем корректно. Решение есть простое, перед тем как кодировать, посчитать в цикле CRC и добавить в конец данных, но не хотелось бы заморачиваться на увеличение данных под CRC когда закидываешь данные на запись. Вот что получилось: // массив данных TestDataWrite50 который надо записать, количество байт 50, суда совсем не хотелось влазить что бы выделять место под CRC StreamWriteDataFlash(TEST1,TestDataWrite50,50); Вот как я планировал сделать, но в данном случае CRC не правильно добавляется (Шапка COBS указывает на конец блока в 50 байт, без учета CRC) //================================================================================================== /* * @Описание: * @Параметр: * @Возврат: */ void StreamWriteDataFlash(uint8_t name,uint8_t *data,uint16_t lenght){ uint8_t Temp; uint8_t LenBalance; uint8_t Tempdata; uint32_t CRC32=0; uint16_t LenCobs=0; //------------------------------------------------ ResetCrc(); //------------------------------------------------ LenCobs=InitCodeCOBS(data,lenght); //------------------------------------------------ CalcShiftHead(name,LenCobs); //------------------------------------------------ for(int16_t i = 0; i<lenght;i++){ //------------------------------------------------ Tempdata=data[i]; Tread_CRC(Tempdata); // CRC //------------------------------------------------ Cobs_encode(Tempdata); // COBS //------------------------------------------------ if(IsCobsCacheFull()){ Temp=PopCobsCache(); Temp=~Temp; PutDataInFlashCache(name,Temp); Temp=PopCobsCache(); Temp=~Temp; PutDataInFlashCache(name,Temp); } } //------------------------------------------------ LenBalance=GetByteInCobsCache(); if(LenBalance>0){ for(uint8_t i=0;i<LenBalance;i++){ Temp=PopCobsCache(); Temp=~Temp; PutDataInFlashCache(name,Temp); } } //------------------------------------------------ //CRC32=GetCRC(); CRC32=~0xAABBCCEE; //------------------------------------------------ //----------В COBS буфер на 4 байта--------------- //------------------------------------------------ Tempdata=CRC32>>24; Cobs_encode(Tempdata); Tempdata=CRC32>>16; Cobs_encode(Tempdata); Tempdata=CRC32>>8; Cobs_encode(Tempdata); Tempdata=CRC32; Cobs_encode(Tempdata); if(IsCobsCacheFull()){ Temp=PopCobsCache(); Temp=~Temp; PutDataInFlashCache(name,Temp); Temp=PopCobsCache(); Temp=~Temp; PutDataInFlashCache(name,Temp); Temp=PopCobsCache(); Temp=~Temp; PutDataInFlashCache(name,Temp); Temp=PopCobsCache(); Temp=~Temp; PutDataInFlashCache(name,Temp); } //------------------------------------------------ PutDataInFlashCache(name,(uint8_t)~0); // Разделитель !!!!!!!! WriteCache_sync(name); //------------------------------------------------ } -
Хранение данных на NOR flash (Кольцевой буфер)
pokk ответил pokk тема в Программирование
Подскажите, как ваш алгоритм на абстракции (модули) делиться. Сначала у меня возникали трудности с адресацией страницы, секторов ... но потом представил что у флеша, есть буфер FIFO(кэш) размером 255 байт, и реализацию его вынес в модуль кэш, и все дальнейшие взаимодействия идут уже на основе функций из этого модуля. void PutDataInFlashCache(uint8_t name,uint8_t data); uint8_t GetDataFromFlashCache(uint8_t name); Так вот теперь встал вопрос, где должен находиться алгоритм с кольцевым буфером ? перед кэш ? или работать на основе кэш ? Если перед кэшом, то как-то все мудрено получается, совсем не представляю как это должно выглядеть. Если алгоритм с кольцевого буфера работает на основе кэша, то тут как бы проще, тогда у кольца получается своя байтова линейная адресация допустим от 0 до 409600 (100 секторов по 4096) байтов (естественно с перебросом адреса в 0 при увеличении ядреса > 409600 ). Но тогда где разместить весь алгоритм стирания сектора дырка, и вообще как кэш завернуть по кольцу. В общем подразумеваю структуру модулей примерно такую: Физические адреса Flash -> кэш -> кольцевой буфер -> файловая система (проверка CRC, шифрование COBS) -
Хранение данных на NOR flash (Кольцевой буфер)
pokk ответил pokk тема в Программирование
Там у вас 4 байта, маркер занятости все 4 байта занимает? Или есть что-то еще? А то я так же заложил 4 байта и только в 1 поставил маркер, а остальные пока не используются, но периодически руки так и чешутся что бы что нибудь туда добавить(подумывал добавить информацию по битно, на записанные страницы, для более быстрого и простого поиска головы), но оказалось это лишнее, голова и так достаточно просто ищется. -
Хранение данных на NOR flash (Кольцевой буфер)
pokk ответил pokk тема в Программирование
Теперь с нахождением головы, стало все ясно. Да я не совсем понял скрытый смысл, почему запись идет с конца. В общем решил отрисовать это, получилось такое: Какакя ешё информация храниться в 4 байтах маркера сектора ?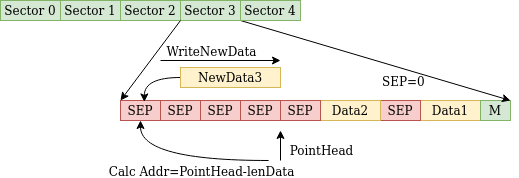
-
Хранение данных на NOR flash (Кольцевой буфер)
pokk ответил pokk тема в Программирование
Почему стертые области ==0 ? После стирания страницы flash вся страница становиться ==0xFF, и записью сбрасываем биты. Расположение блоков COBS внутри сектора сделал так(похоже не много не правильно, но пока не суть)(запись идет от 0 адреса сектора к максимальному): |Data1|0|data2|0|FFFFFF|MARKER| Где data1/2 - блок данных COBS; 0- разделитель между блоками; FFFFFF - свободное место для записи; MARKER- 4 байта в конце сектора Соответственно если искать переход между "==0/!=0", то находим блок с данным Data2, а надо найти свободное место, для записи нового блока данных(COBS). Но походу надо поменять порядок записи, от начала маркера и вниз, с SWAP данными (нулевой элемент массива COBS, у MARKER с дальнейшим уменьшением адреса к 0), тем самым декодирование данных будет проще (сразу получаем указатель на конец блока COBS и его декодируем). Но в любом случае по переходу "==0/!=0" находиться следующий блок данных, а не последний. Да, сделала именно так, байтовый поток пишется в кэш, а дальше по заполнению кэша записываем в flash (либо по завершению функции записи в кэш, если данные < размера кэш ), тем самым полностью абстрагировавшись, от страничной разметки сектора и не важно, какой длины блок записи. При пересечении сектора1/сектора2 так же ? Пока я планировал, перенести блок COBS в другой сектор, если он не влезает,а в том секторе где был хвост забить нулями, тем самым при стирании сектора у нас не возникнет ломаного блока COBS, хотя это самый давнишний блок,можно и потерять его. -
Хранение данных на NOR flash (Кольцевой буфер)
pokk ответил pokk тема в Программирование
А как у вас происходит поиск точного положения головы (смешение внутри сектора)? Как правильно детектировать что после N-го нуля дальше идут не данные а свободная область памяти. 1) Если искать переход 0/0xFF то, 0xFF может быть началом данных следующего блока COBS. 2) Если добавить начальный маркер(отличный от нуля и 0xFF) блока COBS, то тут как бы да переход между 0 и 0xFF, уже говорит о том что это не данные, а свободное место, но положение головы все равно по нему не получается найти, так как такие "хвосты" свободной памяти могут быть в нескольких страницах (когда блок COBS не влез в страницу, и полностью перенеся на следующую страницу). Запись блока COBS собирался делать по странично, если не влезает, на текущую страницу, то записываем на следующую, что бы не разбивать блок COBS и не усложнять алгоритм. PS: Придумал что хвосты можно затереть нулем(разделителем). А если блок COBS, больше размера страницы..., походу придется с разбивкой блока COBS. -
Хранение данных на NOR flash (Кольцевой буфер)
pokk ответил pokk тема в Программирование
Начал подробнее расматривать, часть алгоритма отвечающая за запись блока данных. Для чего используються маркер начала и конца блока данных? И как его макеры правильно добавлять что бы они не совпали а данными? Если декодировать блок данных из COBS , то получаем сразу данные + CRC -
Хранение данных на NOR flash (Кольцевой буфер)
pokk ответил pokk тема в Программирование
Упс мой косяк, сектор с дыркой хотел стерать, а не записывать. Откуда 13 стираний ??? Я описывал ситуацию что каждая 13 итерация сохраненя будет происходит в новый сектор (размер сектор у меня 4096, размер конфигурации примерно 300 байт 4096/300=13) -
Хранение данных на NOR flash (Кольцевой буфер)
pokk ответил pokk тема в Программирование
Я ориентировался на самое большое время, это стирание страницы 80-200ms, когда происходит переход с одного сектора на другой, причем стирать надо 2 сектора для дырки и новый куда буду записываться данные, отсюда и задержка около 400 ms. У меня задача юзер-интерфейса выглядит как в web странице, вводятся данные и нажимается кнопка сохранить, после чего формируется xml запрос с веденным данными и отправляется в процессор. В процессоре, вызывается Callback функция соответственной кнопке web. Внутри функции происходит последовательное модификация конфигурация, запись, верификация(что данные корректно записаны), и возврат статуса записи в web(ответ на запрос) по которому отображается сообщение как произошла запись. В данном случае через 13 сохранений, сообщение об записи отобразиться с задержкой( 400ms), вот это я и назвал "подтормаживание". Ну и задача Callback блокируется на запись, что бы потом отправить подтверждение + зашита от модификации конфигурации, из другого Callback. Особо от этого ни куда не денешься(и буферы тут да не помогают) , по факту стирание странице будет быстрее, и надеюсь это будет не так заметно. PS: а время стирания страници, случайно не зависит, количеста записанной информации в старнице? Пока писал функцию заметил что она выполняеться в 40ms в 2 раза меньше чем указанно в даташите, но там у меня пару 10 байт записанно только было. -
SPI, DMA, как убрать прерывание транзакции?
pokk ответил pokk тема в ARM, 32bit
О т.е 4 байта адреса можно туда загнать, и потом включить DMA на передачу данных ? А какой примерно по размерности там буфер FIFO (2-10 байт или больше ?) А можно краткое описание чем они отличиаються и под какие задачи тот или другой ипользовать? А то сижу на stm32 нефига незнаю =( -
SPI, DMA, как убрать прерывание транзакции?
pokk ответил pokk тема в ARM, 32bit
А если надо передать 1 байт ? Как делаеться ожидание на выставление CS? К примеру что бы разрешит запись во flash надо 1 байт передать. Сначала подумал все просто сделаю так же как DMA на прерываниях, но там получилось что после передачи, буфер TX пустой и прерывания начинают опять генерироваться пришлось включать выключать прерывания, и после всех манипуляций получилось что CS выставляется(в 1), примерно через 1.5 времени передачи байта, не то что бы долго но интересно как сделать по компактнее.