


Nick_K
Свой-
Постов
860 -
Зарегистрирован
-
Посещение
Весь контент Nick_K
-
Давеча попался на глаза неплохой ресурс. Кратко описаны все этапы их задачи и необходимость, без привязки к тулсету (в основном): vlsi-backend-adventure Есть кое-какие небольшие опечатки и неточности, но для старта подойдёт. И да, если нет никакого опыта разработки хотя-бы на FPGA это катастрофически тёмный лес. Боюсь Вы даже не поймёте и половины из описанного.
-
Тут ситуация немного неочевидная, но вся проблема в винчестере. Если 100 us влазит только в оперативку, то 1 ms уже приходится переписывать в кеш HDD/SSD - а это самые большие задержки во всём ПК. Для удобства можно поробобвать не сохранять вейвформы, а поработать с ассертами - если прошли контрольные точки, значит всё ок. Тогда и проект не задержится в памяти и значительно ускорится симуляция. У нас проекты по 3-4 часа симулируются в 1000-1500 потоков, но это немного другая история. Очень хорошим обоснованием есть не время выполнения той или иной функции, а реальная занятость инженера. У меня к примеру только синтез 2-3 часа идёт на удалённом сервере и P&R под 12 часов, я ведь не сижу в это время и бездействую. Можно заняться другими вопросами, симуляцией, проверкой STA и т.д. Я к чему это веду - если 40 минут сборки проекта можно заняться чем-то ещё, тогда не велика проблема, но если комп подвисает что даже тормозит блокнот - это реально проблема и нужно апгрейдить. Хорошее решение - отдельный комп-сервер в локальной сети, на котором собирать проект и уже на своём делать изменения и остальную мелкую работу.
-
Пардон, привык к номенклатуре Xilinx. У Альтеры эта функция называется register retiming.
-
Согласен. Просто на что было приведено пример - на то и ответил) Утром ещё не до конца подгрузилась внимательность)))
-
Внимательный наплюдатель может заметить, что из таблицы истинности выплывает следующая функция для Y: Y=X2 Не знаю какие танци с бубном Вы проводите, но в данном случае нужно или сделать адекватную таблицу входам (2 входа 1 выход - простой лог элемент), либо расширить текущую для больших значений.
-
Попробуйте вкл/выкл register duplication и register balancing, Первое точно для размножения, второе влияет на логику больше.
-
Как раз не обязательно. Из упомянутого могло закрутить критические пути, но чтобы обойти их или соседние соединения не пострадали появляется дублирование компонентов, которое отражается на Утилизации. Ещё момент про Эррату - возможно какие-то комбинации и правду стают запрещёнными и вместо синхронного ресета используется асинхронный ресет через флоп (к примеру). Отсюда так же будет влияние на количество компонентов. И последнее но не маловажное: Новая версия "ласково" подталкивает на переход на новую платформу ибо производителю выгодно, чтобы Вы покупали больше новых компонентов, чем сидели на куче старых. Это может быть скрыто, но проанализировав выходной схематик, наверное можно будет понять где добавляется что-то новое и не совсем нужное.
-
По вопросу сравнения Ква 9 и 13 версии всё достаточно очевидно. Применены дополнительные оптимизации и включены/выключены разные настройки (дефолтно опять же), которые могут сильно влиять на рутинг. С другой стороны возможно произошёл переход алгоритма имитации отжига на квадратично-весовой алгоритм, что значительно затянуло критические пути, но при этом могло спровоцировать большее register duplication или иного рода декомпозицию комбинаторики. Да, в ранних версиях инструментов для P&R начальный плейсмент и вправду брался как псевдорандомное значение. Но стоит учесть, что это значение при константных входных данных (RTL и констрейны) были абсолютно повторяемы на разных машинах и часто даже между минорными версиями.
-
Я предлагаю создать 2,3-да_сколько_угодно частот на одном порте простым объявлением (или дженерейтед клок). Фактически они будудут -logically_exclusive или -physically_exclusive так как одновременно не могут присутствовать, но в завосомости от настроек, будут переключаться. И далее на эндпоинтах (критических точках) уже заниматься конфигурацией необходимых констрейнов для конкретной частоты. Если нигде нет -stop_propagation то по умолчанию все клоки распространяются по всему клоковому дереву, а уже сама IDE должна разруливать подстройку констрейнов под конкретную частоту. Важный момент, если эти частоты генерируются в ПЛИС и выходят наружу, они должны быть обьявлены как частоты, а не как данные (для понимания тулами). Отсюда появится несколько частот по одним и тем же цепям. И да, с ниг придётся сделать ещё виртуальные, так как input/output delay создаётся только к виртуальным частотам. По вопросу насколько это можно - нужно проверить в конкретном IDE. Каденс тулы работают с такими вещами запросто, остальное нужно пробовать. Заодно по результатам расскажете где поднялось, а где нет.
-
Мы делаем немного хотрее. Тул поддерживает несколько клоков в цепях по которым и делается анализ. Так в последнем проекте глобально по всему кристаллу проходило 5 клоковб 2 из которых были отличной частоты от основной. Для каждого клока делался констрейн и прописывался по всем нужным критическим точкам. Ну и понятное дело - не все эндпоинты получали одинаковый набор клоков. Отсюда можете попробовать задать несколько частот и констрейнов под них и сделать эксклюзивными (они ведь физически не могут быть в кристалле одновременно). Возможно у тулзы получится сделать нужные рассчёты и подтянуть нужную времянку.
-
С этим могут быть проблемы, если нет авторизации
-
Не много работал с DDR, но почему-то напрашивается констрейн для input delay, который сам отодвинет нужные события в положительную сторону, при этом настройки клокинг блока по сути останутся теми же.
-
Определение 1/6 числа
Nick_K ответил Valek87 тема в Языки проектирования на ПЛИС (FPGA)
Ещё раз - я опечатался, сдвигать нужно вправо (сдвиг в лево - умножение). В право можно достичь нулевого бита и дальше суммирование сдвинутых данных не окажет никакого влияния на результат. Хотя возможно в таком контексте правильнее говорить, что мы ограничены разрядностью выходного слова. -
Определение 1/6 числа
Nick_K ответил Valek87 тема в Языки проектирования на ПЛИС (FPGA)
Расширить то можно, но если добить нулями, то в определённый момент любой сдвиг вправо перестанет давать результат. То есть вся математика опирается на количество знАчимых разрядов входного числа. P.S. В приведённой мной ранее сумме N=... сдвиг должен быть вправо. Опечатался) -
Попробуйте запустить planAhead и сделать нужные действия вручную. Всё это будет записано в тиклевскую консоль вывода в GUI, откуда можно скопировать в свой скрипт и запустить, немного подтюнив переменные/пути/называния. Не уверен насчёт ISE, но для Vivado поддерживается режим консоли. Фактически происходит запуск среды (IDE) в консоли без открытия проекта, что даёт возможность сорсить все свои скрипты, запускать команды и т.д. Опять же, на форуме Xilinx указано, что с Filter будет значительно быстрее - попробуйте оптимизировать скрипты и свериться с выхлопом planAhead
-
Определение 1/6 числа
Nick_K ответил Valek87 тема в Языки проектирования на ПЛИС (FPGA)
Ну как получится. В пределах разрядности входного числа) Ибо само деление на 6 подразумевает умножение на 0,16-и-6 в периоде. Отсюда приближение. Опять же зависит от задач. Иногда и 64-х разрядов мало, а иногда и 6-7 с головой -
Определение 1/6 числа
Nick_K ответил Valek87 тема в Языки проектирования на ПЛИС (FPGA)
Я не говорил что у него PLL. Присто привёл пример. Такой подход используется во многои схемах. От формирователей импульсов, до частотных преобразователей и ADC/DAC систем. Вы же понимаете, что у ТС и так стоит на выходе счётчик, который и так досчитает до 82. А так придётся ждать 82+3. -
Определение 1/6 числа
Nick_K ответил Valek87 тема в Языки проектирования на ПЛИС (FPGA)
Я привёл пример из реального проекта делителя для PLL. Там математика не нужна и безсмысленна, а входное число меняется каждый отсчёт, так как нужно учитывать термодинамику элементов или изменять выходную частоту. А делитель нужен, чтобы сравнить референс с осцилятором. Праавда у меня челая часть за десятки заваливает, но есть и дробная и работает по тому же принципу. -
Определение 1/6 числа
Nick_K ответил Valek87 тема в Языки проектирования на ПЛИС (FPGA)
Тут вопрос действительно в том, где будет использоваться поделённое число. Если задача стоит в чистом делении и математических операциях, тогда с некоторой точностью можно взять сумму N=(N<<3)+(N<<5)+(N<<7)+(N<<9)... и далее все нечётные значения. Точного деления на 6 не будет, но максимально приближённое получится. Если же нужно поделить значение счётчика и на выходе есть некий интегратор/аккумулятор, тогда точное деление можно получить через Сигма-Дельта Модулятор (SDM). Суть заключается в том, что при делении на 6 будет происходить попеременное деление на 4 и на 8. А точнее выходной счётчик будет считать 2 отсчёта делённого числа на 8 и один отсчёт делённого на 4, в результате интегрирования будет среднее 6. На пальцах: 487 / 6 = 81,16(6) - из примера в первом посте 1. один осчёт на 1/4: 487 / 4 = 121,75 2. плюс отсчёт на 1/8: 487 / 8 = 60,875 ; Усредняем: (121,75 + 60,875) / 2 = 91,3125 (близко но не совсем) 3. и плюс ещё отсчёт на 1/8: 487 / 8 = 60,875 ; Усредняем всё вместе: (121,75 + 60,875 + 60,875) / 3 = 81,16(6) И снова повторить с п.1. Важным условием является наличие выходного интегратора (для PLL, к примеру, используется Low Pass Filter) -
Я не работал с DDR на Альтере, но у Xilinx при подключении RAM во входном "каскаде" нужно использовать частоту, генерируюмую с выхода DDR контроллера, не смотря на то, что он так же питается с внутреннего PLL. А дальше где-то дорисовать CDC или пройти через двухпортовую RAM/FIFO. Насколько я понял там частота (читай фаза) своя со своим клоковым деревом для точной синхронизации.
-
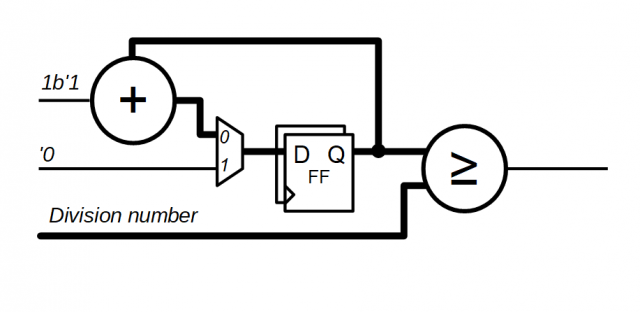
Если DIVIDER - порт, то конечно нет) Всегда придётся вычитать значение от заданного предела. Пример интересный, но здесь получается один сумматор и один вычитатель (который будет оптимизирован с +1). И всё бы ничего, но по экспериментам функция меньше-равно, занимает меньше места в лутах) Можно в обратную сторону считать - не вопрос. Но тогда сравнивать с нулём придётся, при условии что вычитатель немного сложнее сумматора (или вообще CSA для лутов Xilinx). Либо пересчитывать на 1 такт больше, если использовать сигнал borrow.
-
На вычетании 2-ки Вы дополнительно городите ещё один сумматор (вычитатель). Насколько я понял ТС нужен минимальный по площади делитель с максимальной гибкостью. Я сейчас занимаюсь потодного рода проектом и могу с уверенностью сказать, что такая схема будет оптимальна по площади и быстродействию. Единственное ограничение - частота работы => коэфф. деления. Для разрядности 6-10 бит вполне свободно на 100МГц можно уместить (в зависимости от чипа). Для большей разрядности нужно уменьшать частоту работы. По поводу буфферов - да желательно использовать BUFG, но иногда можно и BUFH, коих вполне достаточно для Xilinx чипов.
-
vivado xilinxd
Nick_K ответил Kostochkin тема в Среды разработки - обсуждаем САПРы
Ясно, лицензионные махинации) -
vivado xilinxd
Nick_K ответил Kostochkin тема в Среды разработки - обсуждаем САПРы
Извиняюсь за непросвещённость, но что такое daemon xilinx? -
Многое зависит от технологии (где-то допустимо, где-то нет), но в общем случае да, такое возможно. Если гейт один и вокруг пусто а он сам молотит на бешенных частотах, то он может нагреваться и до 130-150% (по крайней мере я видел такие числа в корнер библиотеках неПЛИСов). И соответственно он будет рассеивать тепло вокруг, что глобально приведёт к меньшей общей температуре. Именно поэтому всё это дело запихивают в печку и нагревают до 85-95-100-130 градусов, чтобы обеспечить равномерное нагревание всех без исключения компонентов и заявить в документации с какой предельной температурой могут работать кристаллы без деградации и с заданными характеристиками. И да, токи утечки и т.п. также оценивают в печках. То есть все компоненты нагревают до +/- одного состояния и меряют затраты. Даже если в данном проекте физически так быть не может, но нужно написать детально в доке, что будет. Вы ведь не хотите, чтобы купленный кристал, с заявленными характеристиками работы на 25 градусов и потреблении условно 1Вт, вдруг в жаркий июньский день резко начал потреблять до 3-4Вт, потому что жарко, а начальник вам зажлобился поставить кондиционер в офис?
