


EvgenyNik
-
Постов
592 -
Зарегистрирован
-
Посещение
Сообщения, опубликованные EvgenyNik
-
-
Слишком мощный выход драйвера может приводить к генерации колебаний на верхних гармониках.
-
А Вы её для хранения и считывания констант хотите использовать? А то из текста можно подумать, что в качестве ОЗУ.внутренней памяти fpga для обработки данных не хватает, поэтому было решено задействовать оставшуюся память флешки (сейчас стоит epcs16) -
Можно поинтересоваться - а с какой целью сие надобно? Если для того, чтобы поставить более мощную пин-ту-пин совместимую ПЛИС, то можно и новую плату собрать...
-
Если допустить, что аналоги имеют иное значение конфигурационных ячеек, нежели исходные чипы, то логично запросить у производителя. Но компилятор то чей? Если забугорный, то он просто не сможет генерировать "дополнительные биты" и тогда всё стандартно.
А гадать по начинке кристалла бессмысленно. В комнате 2 светильника по 5 плафонов - сколько клавиш у выключателя? :)
К тому же, если не включать компрессию, то возможно, файл всегда создаётся максимального размера. Это надо проверить. Загрузочный автомат же может быть очень тупым - перекидал n бит и остановился.
-
Можно. Но сначала надо решить вопрос с требуемой точностью. Результат на выходе фильтра будет зависеть не только от заполнения ШИМ, но и от амплитуды генератора, а та, в свою очередь, может зависеть не только от стабильности источника питания, но и от напряжения на конденсаторе фильтра (если выход слабый).Можно и RC фильтром преобразовать в аналоговый сигнал и подать на АЦП.Опять же, автор не указал - насколько быстро меняется заполнение во времени. Фильтр даст усреднённое значение, фактически, за несколько периодов. А вдруг, у него ШИМ генерирует сложный процесс и ему нужен каждый период.
-
Приходится угадывать, конечно... Шина, случаем, не 5В?
Сталкивался с похожей ситуацией, когда в результате ошибного подключения через пин попадало повышенной напряжение на локальное питание ПЛИС, отчего это питание задиралось и часть логических сигналов просто "проваливались" ниже уровня единицы, т.к. недотягивали.
Есть ещё вариант - всплески напряжения в шине при коммутациях, которые теоретически могут приводить ко всякого рода защёлкиваниям.
-
Ага. Потому что, имея ТЗ на коловорот и подключив всё своё представление о том как бывает плохо, когда что-то не учтено, изобретают дрель с вентильным движком :)а у вас недурная подпись в сообщениях :) так почему?
А я с тем, что он говорит и не спорю.RobFPGA слушать надо :) , дело говорит :)В конечном счёте все тонкости задачи известны только самому ТС. Не в полной мере ясно - что же, всё-таки, требуется: иметь максимально линейный перенос шкалы времени (тогда это больше отводит в сторону счётчиков, интерполяций, цифровых PLL и т.п., реализующих интегральные подстройки) или же чёткое квитирование прохождения определённых этапов (это ближе к фифо и около того).
MegaVolt, а Вы можете написать - в каких пределах могут быть clk1 и clk2?
-
Надеюсь, что будет понятно в продолжение о двух счётчиках, сама идея:
Простой пример (clk1 < clk2)
У нас бегущий секундомер натикивает за 5 секунд значение 7.
Но мы то знаем (по синхросигналу), что должно быть 5.
Делим 7/5=1.4.
Происходит 1ый тик нашего неточного генератора, суммируем
0+1 = 1, это меньше чем 1.4, поэтому счёт вычисленных тиков пока 0.
Происходит 2ой тик, суммируем:
1+1 = 2, что более, чем 1.4, поэтому вычитаем 2-1.4=0.6 и увеличиваем счётчик вычисленных тик 0+1 = 1
3ий:
0.6+1=1.6, 1.6-1.4=0.2, вычисленный 1+1=2
4ый:
0.2+1=1.2, вычисленный сохраняем 2
5ый:
1.2+1=2.2, 2.2-1.4=0.8, вычисленный 2+1=3
6ой:
0.8+1=1.8, 1.8-1.4=0.4, вычисленный 3+1=4
7ой:
0.4+1=1.4, 1.4-1.4=0 (сошлось!), вычисленный 4+1=5 (тоже получили что надо)
Таким образом, мы на 7 тиках вычислили 5 требуемых с каким-то более-менее равномерным распределением.
Другой случай (clk1 > clk2)
Тоже самое, но сейчас наш секундомер отстаёт и за 5 секунд натикивает всего 3.
Делим 3/5 = 0.6
1ый тик: 0+1 = 1, что больше чем 0.6, поэтому считаем 1, разница 1-0.6=0.4
2ой тик: 0.4+1 = 1.4, что более, чем 0.6, поэтому 1+1 = 2, разница 1.4-0.6=0.8, что снова больше, чем 0.6, значит считаем 2+1=3, остаток 0.8-0.6=0.2
3ий тик: 0.2+1 = 1.2, 3+1=4, 1.2-0.6=0.6, 4+1=5, 0.6-0.6=0.
Снова сошлось: за 3 тика насчитали 5.
---
Разница в том, что на ПЛИСке один из счётчиков (тот, на чьё значение надо делить) удобно сделать с фиксированным порогом счёта до числа равно двум в некой целой степени, чтобы делить простым сдвигом.
-
А если так:Пропуски и повторы допустимы если они вызываны разностью частот. И не допустимы если они вызваны тормозами синхронизатора.Интересует решение и для второго случая когда clk1 > clk2
1. В домене clk2 создаём счётчик cnt2 (пусть от 0 до 127)
2. В домене clk1 создаём счётчик cnt1, разрядность которого позволяет с некоторым запасом не "кувыркнуться" через ноль, пока счетчик (cnt2) досчитает до 127
3. При достижении счётчиком cnt2 значения 127, сбрасываемся в 0 и формируем запрос в домен clk1 о передаче значения cnt1.
4. Получив запрос, счётчик cnt1 пересылает своё значение и сбрасывается в 0.
5. Таким образом, мы получаем какое количество тактов clk1 накапливается в счётчике cnt1 за время, пока счётчик cnt2 считает интервал в 128 тактов clk2.
6. Представив это значение в формате с фиксированной точкой мы получаем масштабный коэффициент, позволяющий вести эквивалентный счёт от тактов clk2 с представлением времени в домене clk1 в течении следующего интервала, пока не произойдёт обновление информации.
Пример:
cnt2 пробежал интервал в 128 тактов clk2, присланное значение cnt1 = 2309 clk1
Считаем 7 младших бит - дробной частью, тогда в десятичных получаем cnt1/cnt2 = 18,0390625.
Теперь на каждый такт clk2 мы прибавляем к образе cnt1 значение 18,0390625:
18,0390625, 36,078125 и т.д.
На следующем интервале cnt1 покажет число 2314, к примеру, и мы скорректируем наш масштабный коэффициент.
-
Да, это запрос-ответ. Но иЭто я так понял запрос ответ с синхронизацией. Многовато кодов пропускает :(
работало бы на такой же "скорости обмена".Для однобитного счётчика это позволяет реализовать обычный синхронизатор правда при условии что первая частота меньше второй.Чтобы пропускало меньше кода надо для счёта использовать не саму частоту тактирования, а поделенную на 2..4.
-
FIFO не подойдёт, т.к. подразумевается разница частот, а значит буфер или переполнится или будет пустым.
module cnt_copy ( input clk1, input clk2, output reg [7:0] cnt1, output reg [7:0] copy2 ); reg ready1 = 0; reg ready2 = 0; reg ready1_l1, ready1_l2; reg ready2_l1, ready2_l2; reg [7:0] cnt1_l; always @ (posedge clk1) begin ready2_l1 <= ready2; ready2_l2 <= ready2_l1; cnt1 <= cnt1 + 1; if (ready2_l2) begin if (~ready1) begin cnt1_l <= cnt1; ready1 <= 1'b1; end end else begin ready1 <= 1'b0; end end always @ (posedge clk2) begin ready1_l1 <= ready1; ready1_l2 <= ready1_l1; if (ready1_l2) begin if (ready2) begin copy2 <= cnt1_l; ready2 <= 1'b0; end end else begin ready2 <= 1'b1; end end endmodule
Результат

Указать таймбара стоит, как раз, на моменте, начиная с которого происходит передача значения "3". Далее тоже видно как передаются значения. С пропусками из-за синхронизации, но без искажения передаваемого значения.
-
У MAX 10 есть на борту PLL. У него есть выход Locked. Даже если Вам "услуги" PLL не нужны, то можно завести клок на него только ради этого сигнала, чтобы обеспечить начальный сброс регистров в исходное положение стандартными средствами (подобие ресета).
Не факт, что в дальнейшей поддержке не придётся в угоду фиттеру играться с настройками компилятора. Обнаружите, к примеру, что с галочкой Ignore initial проект весит меньше, обрадуетесь. И только когда-нибудь где-нибудь вылезет некорретная работа.
-
Первая мысль, которая возникла - ограничивают мощность на выходе (потому и на более низком TTL ток можно развить выше). Но величина 16мА уже на 3.0В указывает, что дело не просто в ограничении мощности.Ток всего 2 миллиампера - но почему так мало? LVTTL не многим лучше - даже до 16 ма не дотягивает :(Насколько я понимаю - это не ошибка, и 3.3 вольтовые драйвера очень слабые?
Вероятно, дело в том, что последние поколения ПЛИС всё хуже и хуже справляются с перенапряжением (пусть и кратковременным) на выводах. И чтобы не создавать перенапряжения при коммутациях в области уровней, близких к критическим, ток там ограничивается.
Как-то убил Циклон, вогнав в резонанс RLC-нагрузку на выходе 24МГц. На живом другом глянул - примерно 6В в амлитуде от выхода 3.3! Снизил ток в порядке эксперимента - помогло.
А вообще, от силового применения выходных каскадов ПЛИС надо уходить.
У MAXII/V тоже разброс был неслабый 3.33-5.66МГц. Для простых вещей хватает. Кстати, если есть некий внешний периодический низкочастотный сигнал, то при расположенности к искусственным трудностям :), можно заделать цифровую подстройку, потратив десятков 5-7 логических ячеек.Встроенный осциллятор тоже расстроил - генерирует частоту в диапазоне 55-116 МГц, без возможности выбрать более точное значение. -
always @ (negedge clk) begin if (stage_r == 0) wramag_r <= 1; // это нужно, чтобы избавиться от глитча при возврате из режима записи (см. формирование wram_o) else wramag_r <= 0; end
Подскажите вот это как в граф редакторе на триггере реализовать?
Фактически, здесь написано: всегда при отрицательном фронте clk присваивать wramag=1, если stage равен 0 и, если иначе, то обнулять этот wramag.
Так и делаем:
1. инвертируем clk (надо же по отрицательному фронту защёлкивать) и подаём на тактовый вход DFF
2. биты stage заводим на ИЛИ-НЕ и подаём на вход данных D
3. защёлкивам в DFF
4. снимаем результат с Q
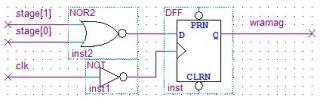
p.s. А зачем Вам манипуляции с OE и CS? Если используется один чип памяти и его порты работают через ПЛИС, то пусть по умолчанию всегда будет выбран и всегда в режиме выдачи данных с текущего адреса. Ему (чипу ОЗУ) всё равно, а Вам - экономия ресурсов на ПЛИСке.
-
Создайте графический символ этому файлу и вставьте в свой проект. Может, ещё и не заработает. Чего зря рисовать то?
-
Да.Вам для серийного производства?Разработать и производить можем сами. Просто хотелось для стартапа не совершать лишние телодвижения, т.к. и без этого работы полно.
-
Спасибо. Понятно. Думал за 1 такт можно ухитриться, но видать нет (
Попытка - не пытка.
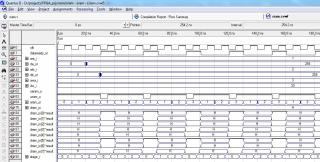
module sram #( parameter wdata = 8, parameter waddr = 10 ) ( input clk, input [waddr-1:0] ara_i, arb_i, awa_i, input [wdata-1:0] dw_i, output reg [wdata-1:0] da_or, db_or, inout [wdata-1:0] dram_io, output reg [waddr-1:0] aram_or, output oeram_o, output wram_o, output reg dataready_or ); assign oeram_o = 0; assign dram_io = (we_r ? rwram : {waddr{1'bz}}); assign wram_o = (we_r ? ~clk | wramag_r : 1'b1); reg [wdata-1:0] rwram; reg we_r; reg wramag_r; reg [1:0] stage_r; always @ (posedge clk) begin if (stage_r == 2'b10) stage_r <= 0; else stage_r <= stage_r + 1; case (stage_r) 2'b00: begin aram_or <= ara_i; we_r <= 0; dataready_or <= 0; end 2'b01: begin aram_or <= arb_i; da_or <= dram_io; rwram <= dw_i; end 2'b10: begin aram_or <= awa_i; db_or <= dram_io; we_r <= 1; dataready_or <= 1; end endcase end always @ (negedge clk) begin if (stage_r == 0) wramag_r <= 1; // это нужно, чтобы избавиться от глитча при возврате из режима записи (см. формирование wram_o) else wramag_r <= 0; end endmoduleС времянками, конечно, получается вольно и лишь бы сама ОЗУшка успевала.
-
Возможно. Потому что сейчас не понял яПовторюсь: возможно, я чего-то не понял.
Покажу с помощью "наскальной живописи".
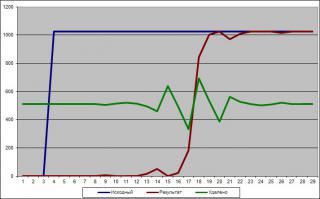
Вот результат подачи ступеньки на режекторный фильтр. Вырезанная часть специально приподнята к средней линии.
Фактически, если сложить то, что вырезано с тем, что осталось, то получится исходный сигнал (за вычетом округлений, т.к. в процессе фильтрации приходится разрядность увеличивать в "дробную сторону", а потом возвращать обратно округлением, и прочего по-мелочи навроде ограничения от выходов в минус и за пределы разрядности вверх), естественно, смещённый по времени.
Однако, если задача поставлена - оставшиеся компоненты поместить в те позиции, где они были, то фронт получившегося отклика мы подтаскиваем к фронту исходного и вот теперь виден "хвост до собаки" :)
-
Так-то всё верно, конечно, когда процесс происходит во времени.Попытка применить метод, не предназначенный для анализа конечного по времени сигнала, для упрощения условно принятого бесконечно повторяющимся, дает "на бумаге" указанный эффект. В реальности же необходимо учесть, что в нашей вселенной скорость света физический предел и "хвост" все равно останется на своем месте, а именно после собаки.Но смотрите, вот какой пример. У нас есть некий массив с последовательностью, описывающей мгновенные значения многокомпонентного сигнала. Задача - вырезать какую-то частоту, сохранив для остальных одинаковое время групповой задержки. Создаём режекторный фильтр. Прогоняем через него массив и (а вот это важно!) складываем результат так, чтобы оставшиеся компоненты легли по тем же местам, где находились до режекции. Результат - из прежней последовательности удалена ненужная компонента, а остальное не тронуто.
Что ожидаемо, но, всё равно, интересно - если из исходного массива поточечно вычесть новый, то получится вырезанная компонента. Причём, иногда таким "косвенным" способом её получается выделить даже лучше, чем полосовым фильтром.
Понятно, что такое возможно только в отложенном времени. И даже когда делается налету, то только через буферизацию.
Однако, если если в этот алгоритм подсунуть ступеньку, то будет то, о чём я писал ранее - реакция появится "ранее".
-
Дык, Вам и пишут - как из обычного 100МГц ОЗУ сделать а-ля двухпортовое 50МГц ОЗУ. Только порты будут фактически на ПЛИСке.У меня не двух портовая память... -
ТС в середине темы уточнил:Надо понимать, что не зная частоты, считать сколько периодов сигнала имеется в наличии весьма интересный подход из разряда "если сейчас из ямы не вылезу - побегу домой за лестницей")))
А это значит, что примерно, всё-таки, известно. Более того, более-менее стандартны интервалы времени, на которые энергосистема может вываливаться на величину конкретного отклонения.Речь идет об электрораспределительной сети.В сети всегда есть основная гармоника и гармоники до 13-й, но основная всегда около 50 Гц, например 45-55 Гц.
-
Так же, как и при разложении в ряд Фурье, составляющие компоненты начинаются раньше, чем фронт раскладываемого сигнала. И только, будучи сложенными вместе, образуют его в первозданном виде. А если мы часть из них вырезаем, то, как раз, и получаем "хвост спереди".Правильный ответ таков: отклик идеального фильтра на любое воздействие наступит раньше (Sic!) этого самого воздействия.В современности, когда многие задачи решаются в цифре и в отложенном времени, это "раньше самого воздействия" уже не только возможно, но и даже используется.
Сделав однажды подобный фильтр и демонстрируя заказчику его переходную функцию, тоже получил вопрос: как это так - ступеньки на входе ещё нет, а какие-то колебания уже есть? Предложил ему разложить прямоугольный импульс в ряд Фурье, исключить оттуда вырезаемые частоты и снова сложить... А поскольку вычислению с массивами неведомо прошлое и будущее, то там гром раньше молнии - явление вполне реальное.
-
Ну тогда читать Вам надо по системе "запрос-ответ". Т.е. некий мастер выставляет запрос на чтение по определённому адресу, ваша ПЛИС "принимает" этот запрос и ожидает паузы между записями. Наступает пауза максимум через 4 такта, Вы читаете из ОЗУ и выставляете готовность - "забирай" :)Читать я буду на частоте 10Mhz вот такой расклад получается, но проблема то в том что у меня 2 клоковых домина пересекающийся между собой!Более того, учитывая, что читаете Вы на 10МГц, у Вас, как навскидку думается, есть все шансы - обработать "запрос на чтение" в этом же цикле чтения, не заставляя читающее устройство ждать.
-
Но данные приходят по 8 бит, а ширина шины данных ОЗУ 16 бит, что даёт ему возможность накопить слово и записать его одним махом. А пока оно копится - прочитать 16 бит для выдачи.Если основной клок 100МГц и данные поступают на каждом втором такте - то у Вас просто нет шансов даже на запись - каким образом сформировать управляющие сигналы?



Почему от генератора всё работает
в Работаем с ПЛИС, области применения, выбор
Опубликовано · Пожаловаться
Встретился мне как-то (давно ещё) такой случай, когда вместо обычного шинного формирователя (АП5, АП6, 244, 245) поставили какой-то очень быстрый и на шине данных стали возникать ошибки. Оказалось всё просто - сигналы RD и WR приобрели излишнюю колебательность и как бы поступали дважды на управляющие входы.