EvgenyNik
-
Постов
592 -
Зарегистрирован
-
Посещение
Весь контент EvgenyNik
-
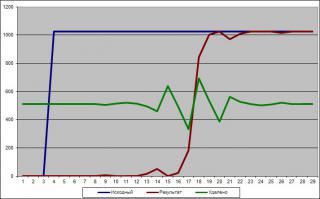
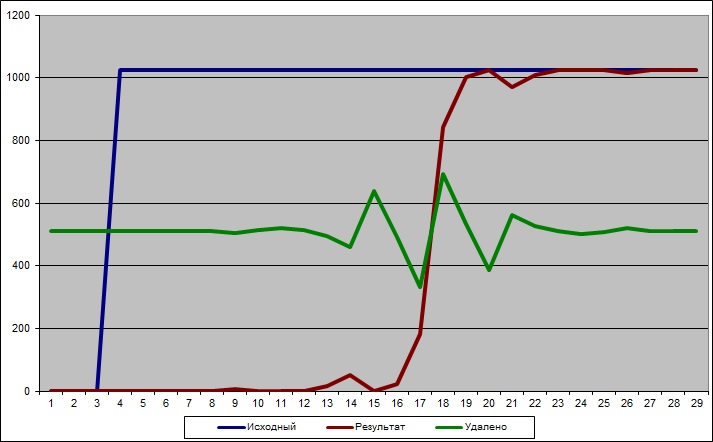
FIFO не подойдёт, т.к. подразумевается разница частот, а значит буфер или переполнится или будет пустым. module cnt_copy ( input clk1, input clk2, output reg [7:0] cnt1, output reg [7:0] copy2 ); reg ready1 = 0; reg ready2 = 0; reg ready1_l1, ready1_l2; reg ready2_l1, ready2_l2; reg [7:0] cnt1_l; always @ (posedge clk1) begin ready2_l1 <= ready2; ready2_l2 <= ready2_l1; cnt1 <= cnt1 + 1; if (ready2_l2) begin if (~ready1) begin cnt1_l <= cnt1; ready1 <= 1'b1; end end else begin ready1 <= 1'b0; end end always @ (posedge clk2) begin ready1_l1 <= ready1; ready1_l2 <= ready1_l1; if (ready1_l2) begin if (ready2) begin copy2 <= cnt1_l; ready2 <= 1'b0; end end else begin ready2 <= 1'b1; end end endmodule Результат Указать таймбара стоит, как раз, на моменте, начиная с которого происходит передача значения "3". Далее тоже видно как передаются значения. С пропусками из-за синхронизации, но без искажения передаваемого значения.

-
MAXII + SRAM
EvgenyNik ответил zombi тема в Работаем с ПЛИС, области применения, выбор
Фактически, здесь написано: всегда при отрицательном фронте clk присваивать wramag=1, если stage равен 0 и, если иначе, то обнулять этот wramag. Так и делаем: 1. инвертируем clk (надо же по отрицательному фронту защёлкивать) и подаём на тактовый вход DFF 2. биты stage заводим на ИЛИ-НЕ и подаём на вход данных D 3. защёлкивам в DFF 4. снимаем результат с Q p.s. А зачем Вам манипуляции с OE и CS? Если используется один чип памяти и его порты работают через ПЛИС, то пусть по умолчанию всегда будет выбран и всегда в режиме выдачи данных с текущего адреса. Ему (чипу ОЗУ) всё равно, а Вам - экономия ресурсов на ПЛИСке.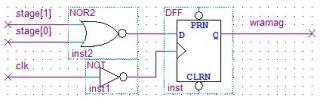
-
MAXII + SRAM
EvgenyNik ответил zombi тема в Работаем с ПЛИС, области применения, выбор
Попытка - не пытка. module sram #( parameter wdata = 8, parameter waddr = 10 ) ( input clk, input [waddr-1:0] ara_i, arb_i, awa_i, input [wdata-1:0] dw_i, output reg [wdata-1:0] da_or, db_or, inout [wdata-1:0] dram_io, output reg [waddr-1:0] aram_or, output oeram_o, output wram_o, output reg dataready_or ); assign oeram_o = 0; assign dram_io = (we_r ? rwram : {waddr{1'bz}}); assign wram_o = (we_r ? ~clk | wramag_r : 1'b1); reg [wdata-1:0] rwram; reg we_r; reg wramag_r; reg [1:0] stage_r; always @ (posedge clk) begin if (stage_r == 2'b10) stage_r <= 0; else stage_r <= stage_r + 1; case (stage_r) 2'b00: begin aram_or <= ara_i; we_r <= 0; dataready_or <= 0; end 2'b01: begin aram_or <= arb_i; da_or <= dram_io; rwram <= dw_i; end 2'b10: begin aram_or <= awa_i; db_or <= dram_io; we_r <= 1; dataready_or <= 1; end endcase end always @ (negedge clk) begin if (stage_r == 0) wramag_r <= 1; // это нужно, чтобы избавиться от глитча при возврате из режима записи (см. формирование wram_o) else wramag_r <= 0; end endmodule С времянками, конечно, получается вольно и лишь бы сама ОЗУшка успевала.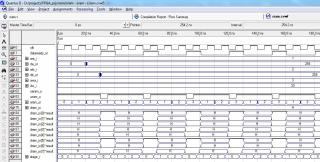
-
Старый вопрос
EvgenyNik ответил Милливольт тема в Алгоритмы ЦОС (DSP)
Возможно. Потому что сейчас не понял я Покажу с помощью "наскальной живописи". Вот результат подачи ступеньки на режекторный фильтр. Вырезанная часть специально приподнята к средней линии. Фактически, если сложить то, что вырезано с тем, что осталось, то получится исходный сигнал (за вычетом округлений, т.к. в процессе фильтрации приходится разрядность увеличивать в "дробную сторону", а потом возвращать обратно округлением, и прочего по-мелочи навроде ограничения от выходов в минус и за пределы разрядности вверх), естественно, смещённый по времени. Однако, если задача поставлена - оставшиеся компоненты поместить в те позиции, где они были, то фронт получившегося отклика мы подтаскиваем к фронту исходного и вот теперь виден "хвост до собаки" :)