el.d
-
Постов
42 -
Зарегистрирован
-
Посещение
Весь контент el.d
-
Скляр, разомкнутые символьные синхронизаторы
el.d опубликовал тема в Алгоритмы ЦОС (DSP)
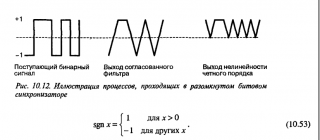
Здравствуйте. Возникли вопросы по тексту издания 2003 года книжки Скляра "Цифровая связь" (стр. 646-647). Схема и ряд поясняющих к ней картинок прилагается. 1. Судя по поясняющей картинке и тексту главы (по тексту написано некое "квадратичное устройство") , "нелинейность четного порядка" = возведение в квадрат выхода СФ. Поправьте пожалуйста, если ошибаюсь. 2. Получается, что на выходе нелинейности имеем гармонику в спектре сигнала на частоте тактового генератора. То есть, например, если я имею clock = 20 МГц и полосу сигнала 8 МГц, то для выделения синхронизированного сигнала мне нужен полосовой фильтр с центральной частотой 20 МГц и еще захватить 4 МГц влево-вправо от неё. Однако, если честно, не совсем понимаю как такой фильтр применять. Тактовая частота 20 МГц, и частота дискретизации отсчетов, поступающих на СФ, тоже 20 МГц. Получается, что цифровым фильтром я могу фильтровать от 0 до 10 МГц при таком раскладе. Получается, что надо перед полосовым фильтром поднимать частоту дискретизации? Я правильно понял? И еще: пользовался кто-нибудь данной схемой синхронизации? Если да, то был какой-нибудь ощутимый результат?